Wincer's Blog ATOMWincerHugo2024-07-22T11:46:00Zurn:uuid:f4128825-6c8c-52c7-d9ca-9d428878c613又一次博客优化记录2024-07-22T11:46:00+08:002024-07-22T11:46:00+08:00urn:uuid:01a1f4c7-0dfb-56f0-19e2-67a17bce01ff
在运行生成地址的算法时,显卡相比 CPU 有很大的优势:显卡的流处理器相比 CPU 有数量级别的优势,因此使用 GPU 来生成虚荣地址会更快速。网上找了一圈,虽然 Solana 也有
solanity
这款使用 CUDA 编写的工具,但是我使用 RTX 3080 运行的生成其实和我用 CPU 跑不出什么多大的区别(issue 也有人反馈根本达不到预期的性能),而我在使用
profanity2
这款 OpenCL 编写的 ETH 虚荣地址生成工具运行速度是相比 CPU 有数量级的差距。因此我便开始研究生成地址用到的加密算法,打算自己写一个出来。
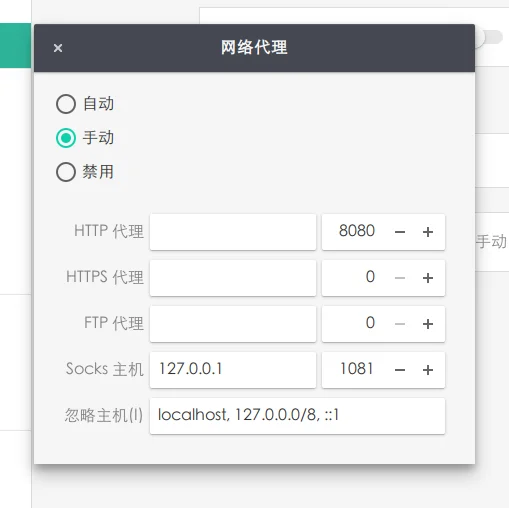
本质上 Clash 只是一个代理工具,无法确保在电脑上运行的各个程序的流量都由代理转发——很多软件的网络设置是不经由系统代理的,尤其是在终端的应用:pnpm,go get,curl,brew,ssh,这在软件开发的时候其实还挺烦人的,还需要单独为每一个应用设置代理,不同应用的配置方式还不一样。Clash X Pro 提供的增强模式算是一个解决方案,不过同样也已经下架了。
对于第一点,其实 Quantumult X 就做得很好,分流的规则以及机场的节点是分开配置的,而且无论你有多少不同机场的节点,你都可以通过新建一份分流规则来在所有节点之中切换,而且新建的分流规则并不会被机场本身定时更新的订阅所覆盖。
对于第二点,其实是代理工具和 VPN 的区别,像是 Cisco Anyconnect 这种 VPN 工具,会新建一个虚拟网卡,并新增一条路由规则让所有应用的流量都流经此网卡,也就不再需要单独为不同的应用设置代理选项了。Clash X Pro 的增强模式也是使用这样的解决方案。
]]>
使用 Hugo + SolidStart 重构博客2023-05-07T06:01:23+08:002023-05-07T06:01:23+08:00urn:uuid:e0bc1947-6783-5cfb-b944-e7a18947be59
在去年年底时,我
重新设计
了一版博客的主题,不过此版主题主要是针对 UI 样式方面的调整,底层的架构没有变化:静态内容还是 Hugo 生成,动态内容如:搜索、消遣页面,暗色模式、评论等功能则是由 Svelte 提供支持。这个技术栈使用起来其实挺搭的:Svelte 打包后的结果很小,生成的 JavaScript 文件直接在 Hugo 模板中用一个 script 标签引入就行了。
那么,是什么原因让我仅仅时隔半年的时间就再次重构博客呢?让我先卖一个关子,先说一下 Hugo 的一些问题。
Hugo的缺点
Hugo 其实本身的集成度很高了:模板生成、静态资源打包、自定义的输出格式等功能都有。但有两点我用着不是特别舒服。
开发体验
Hugo 主题的开发体验太差了,差的体验其实都和它的生态相关。
VSCode 的插件本身提供的功能非常有限:文件跳转不行、语法高亮残废、代码补全仅限于一些基础的 snippet。而且因为 Hugo 的 template 是扩展的 HTML 语法,如果写了稍微复杂一点的 Hugo 表达式,在保存自动格式化时有时候会按照 HTML 的语法缩进,导致表达式的出现语法错误,这时候只能在右下角将语法切换为 Plain Text,然后再保存。
Hugo 本身本身虽然具备 JavaScript 和 Sass、SCSS 文件的打包功能,但其实支持都比较有限:
JavaScript 的打包是由 ESBuild 提供支持,但是你不能在 Hugo 中添加 ESBuild 的插件;
Hugo 内部具备了非常多的功能,但是就像一个黑盒一样是集成在它内部的,我三年前从 Hexo 切换过来的时候,正是看中了它这一点,但直到我自己开发起来我才发现这其实并不是什么好事。因为有些功能你总会需要自己来定制实现的,比如博文加密、构建前后的 Hook、针对某些元素自定义渲染等,这种功能可能并不是每个人都会用到,开发组不做也很正常,但是我觉得 Hugo 的开发组对此的态度也有一点奇怪。
很早之前我在寻找 Hugo 博客加密的方案时,曾经想过一个方法就是在 Hugo 渲染的时候调用外部的可执行文件或者脚本(Shell 或者 .go 文件),于是我就搜了一下,发现早在 2015 年就有人提了 Issue,开发者一开始也认为这个想法很赞,不过还是出于安全(?)以及兼容性的考虑放弃了这个做法,并把这个 Issue locked 了。开发组对不同平台的兼容性有顾虑这一点还是有道理的,不过说出于安全的考虑我真的是没搞懂,开发组似乎是担心有人在主题文件里的可执行的脚本加入了恶意代码,执行起来就会导致设备中毒或者删除数据之类的,乍一看好像还挺有道理的,可仔细一想完全不通啊。哪个语言的包管理器都支持从网上下载代码啊,怎么难道他们都不担心下载的是恶意代码吗?
另一个让我不喜开发组的例子是 Markdown 元素的自定义渲染,目前仅支持有限的渲染:标题标签、超链接标签、图片标签、代码块标签(这个还是最近加上的),当询问到为什么不支持更多的标签自定义渲染的时候,开发组说因为担心渲染的性能问题,所以只开放了这几个,可 Hugo 的渲染速度真的很快很快了,我博客的近三百个页面,只需要 120 ms 的时间就可以全部生成,就算加上所有的标签的自定义渲染会牺牲 50% 的性能,我认为大多数的人都是可以接受的,甚至他们根本感受不到区别。
开发组的态度,加上 Hugo 本身像是一个黑盒,所以 Hugo 的生态其实很差,仅仅是包括一些主题而已,任何针对 Hugo 本身功能上的扩展都没有。
Anyway,吐槽归吐槽,用还是得继续用下去。(几年前迁移到 Hugo 时都说了 Hexo 再也不见了,难道还能删文自己打脸不成?
让 Hugo 回归本质
“什么是 Hugo 的本质?”
“内容生成和模板渲染。”
因此本次重构我只使用 Hugo 生成文章的内容,不包含任何样式、脚本等,输出格式我选择了 JSON,包含渲染后文章的主体内容,还包含了文章的元信息以及下一篇、上一篇等额外字段。
这些 JSON 文件,就是后续网站构建的内容核心。
为什么重构?
扯了这么久 Hugo 的缺点,其实本次的重构的缘由并不是我完全无法忍受这些缺点了,只是单纯想吐槽一下,又觉得为了吐槽单独写一篇文章有点没必要,于是就在这里写了。本次重构的主要原因是我想稍微系统地学一下前端目前的主流框架,并且利用现代的 Web 开发技术来提升一下博客的用户体验。
当用户初次进入网站或点击刷新的时候,首先会从 localStorage 中载入用户的选择,如果不是 auto,那么就直接把 html 标签的 class 设置成对应的值;如果是 auto,就用当前系统的模式。这部分的逻辑,是我单独抽出来的放在 head 标签里的,并没有和 JSX 组件放在一起:因为组件是在 DOM 加载完成后才渲染,如果这部分也放在组件逻辑中,那么页面可能会在组件渲染时出现闪烁的情况。
等到 JSX 组件加载完成后,theme 相关的逻辑会首先执行,它会直接使用 html 的 className 来作为初始值。
切换成现有架构后我发现了在页面切换时存在的一个问题,当用户点击页面时,会有几百毫秒的停顿时间,这期间是在等待加载渲染新页面所需的资源,而在当前页面也没有任何变化,这会让用户怀疑是不是没有点击或者网络出问题了。对比传统的静态页面,点击 a 标签时,左上角的刷新图标和标签 tab 会转圈给用户反馈表示新页面正在加载。
几年前,我专门组过一台电脑折腾黑苹果与 Windows 双系统,之后便一直稳定用到现在(没有手贱乱升级)。最近发现硬盘已经快占满了,500G 的空间还要分一半给 Windows 用,也真是难为它了。正赶上固态价格大幅跳水,于是我买了一块 2T 的固态来升级硬件配置,正好心里也想顺便升级一下软件来体验最新版的 macOS Ventura,是以写下这篇文章作为记录。
#######################################################
# MountEFI #
#######################################################
1. EFI | 209.7 MB | EFI | disk0s1
2. Core | 249.3 GB | Microsoft basic data | disk0s3
3. macOS | 250 GB | APFS | disk1s5s1
4. Install macOS Ventura | 15.8 GB | Mac OS Extended (Journaled) | disk2s1
5. Shared Support | 12.2 GB | Apple HFS+ | disk3s2
S. Switch to Full Output
B. Mount the Boot Drive's EFI
L. Show diskutil list Output
D. Pick Default Disk (None Set)
M. After Mounting: None
R. Toggle Window Resizing (Currently Enabled)
Q. Quit
Pick the drive containing your EFI: 4
我这里选择 4,代表刚刚刻录了 macOS 的 U 盘,可以看到 U 盘名字被安装程序自动更改成了 Install macOS Ventura。随后打开 Finde 就能看到 EFI 分区被挂载上了。
macOS 下,确实没有一个像 Rufus 一样好用工具来制作镜像,像 Etcher 这种工具是无法用来制作 Windows 11 的安装镜像的。
这篇教程
提供了一个比较好的方法。总结下就是:给 U 盘格式化成 MS-DOS(FAT)格式带 GUID 分区表,然后把 Windows 11 镜像的 sources/install.wim 这个超大的文件用工具切割成两个小一点的文件,不然就超过了 FAT 最大文件 4G 的限制。
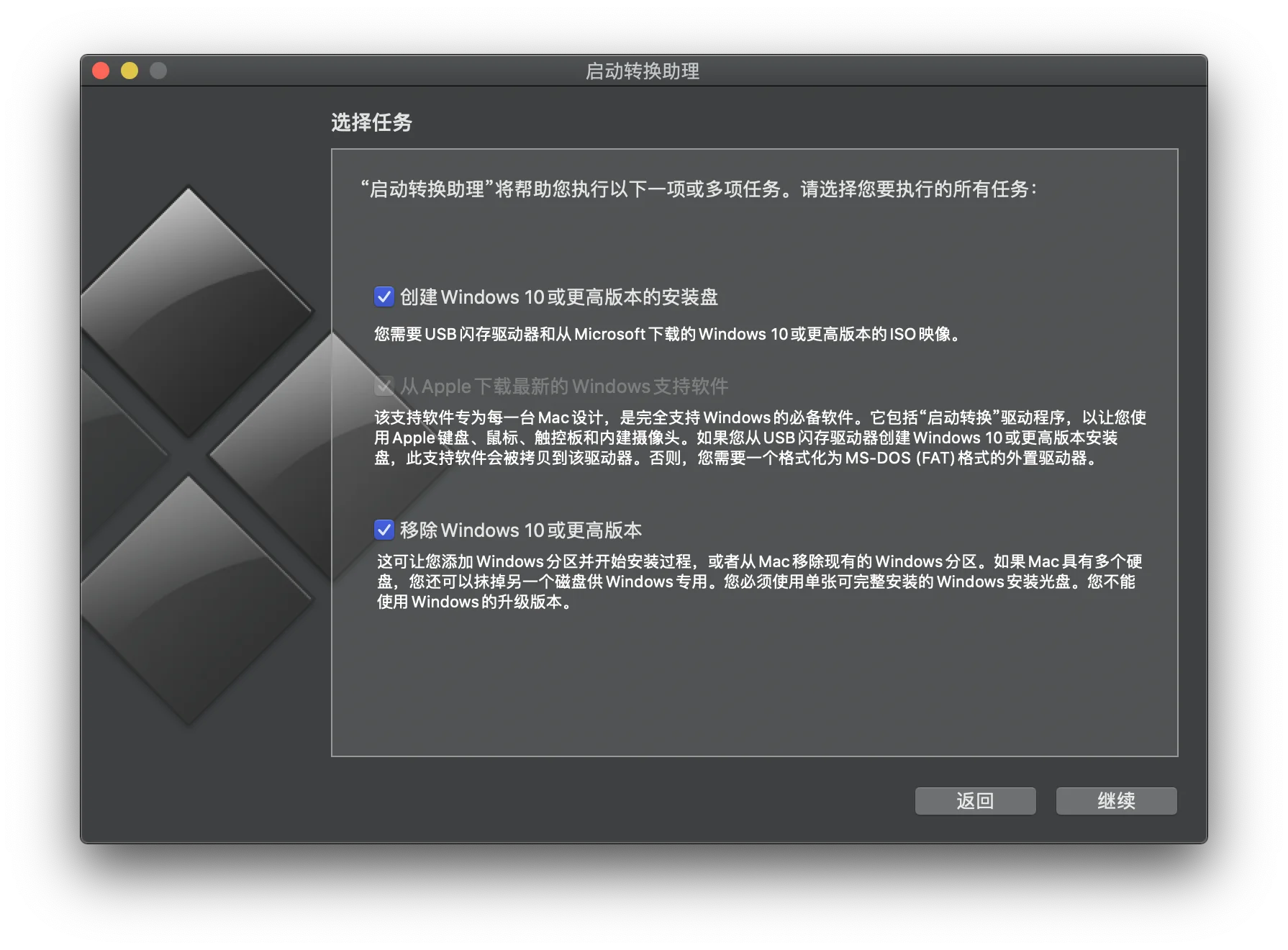
启动转换助理
打开启动转换助理,接下来选择镜像以及配置 Windows 分区大小(如果你插着 U 盘,可能会提示让你拔掉,暂时拔掉即可),在等安装完成后会重启电脑,目前 Windows 11 的镜像没有自带可引导的分区,所以重启电脑后会发现找不到 Windows 的安装入口,这时选择进入 macOS 系统,如果这里出现了 Windows 安装分区,也不要进入!
再次打开启动转换助理,在左上角菜单操作菜单 -> 下载 Windows 支持软件,保存在 U 盘中。
分区 & 安装
打开 macOS 的磁盘工具,给现有的磁盘分出一块分区来,分区格式随便选,反正一会 Windows 安装的时候要把分区重建。如果上一步骤你已经通过启动转换助理做了分区,这里的分区步骤可以跳过。
分区完成后,重启电脑,关键的步骤来了:按 F12 进入 BIOS 的启动引导项,然后选择 U 盘,注意这里不要通过 OpenCore 的引导项选择 U 盘然后进入安装界面。
如果直接通过 OpenCore 的引导项选择 U 盘进入的安装界面,大概率会安装失败,原因猜测是 Windows 安装的时候从 BIOS 拿到的 ACPI 文件与 OpenCore 本身加载的 ACPI 文件冲突了。
为什么我会这么猜测呢,因为很明显从 OpenCore 进入 Windows 安装界面的话,分辨率是 4K 的,而如果从 BIOS 进入 Windows 安装界面的话,分辨率模糊的一塌糊涂。
Windows 11 的安装程序需要添加 BypassTPMCheck 和 BypassSecureBootCheck 这两项注册表才能运行,如果你有 Windows 设备的话,可以用 Rufus 来刻录 Windows 11 的镜像,他会自动帮你跳过这两个检测。随后在选择安装位置的时候,定位到刚刚的那块硬盘分区,把它删除掉,分区会显示成未分配,选择安装 Windows 到此分区即可。
Windows 支持软件
在 Windows 安装程序拷贝文件完成之后,会自动重启,并修改 BIOS 的启动项顺序,把 Windows 的启动引导放在第一位,所以这里会继续进入到 Windows 的安装界面(伴随着模糊的分辨率),等待安装完成后,这时不要急着装驱动,也不要运行我们的 Windows 支持软件,直接运行的话会失败。
这里同样还是因为 ACPI 的原因,因为我们直接通过 Windows 启动引导进入的系统,没有使用 OpenCore 中的 ACPI 文件,而 Windows 支持程序会检测当前操作系统是否使用的苹果的 ACPI 文件启动。
设置完成后会再次重启,这时可以进入 BIOS,调整一下启动项顺序,把 Windows 的启动项放在后面(或者直接禁用了),OpenCore 的放在第一位。然后重启就会进入到 OpenCore 的引导菜单了,这时就可以看到 Windows 的菜单项了,选择 Windows,然后进入系统后,打开 U 盘下载的 Windows 支持软件,进入到 BootCamp 文件夹,点击 Setup.exe 安装。
完成后,双系统就成功了,可以从 Windows 启动到 macOS,也可以从 macOS 启动到 Windows 而不需要在引导菜单的时候手动选择。
当然。开启了 NVRAM 的支持是前提。
注意事项
备份
所有 OpenCore 的配置完成后,苹果系统已能正常工作时,一定要把你的 EFI 分区备份一下。另外可以再准备一个 U 盘,格式化成什么格式无所谓,只需要带有 GUID 分区表即可,然后将目前黑苹果的 EFI 分区给备份到 U 盘上的 EFI 分区。
这样万一引导分区出现什么问题导致无法启动,重启电脑按 F12 从引导菜单选择 U 盘(这里需要从 BIOS 引导菜单选择 U 盘,而不是从 OpenCore 引导菜单选择 U 盘)也能进入系统及时修复。
于是兜兜转转我还是回到了找云服务商提供的语音识别方案上,找了半天,终于找到了一款 Python 的开源库
SpeechRecognition
,虽然是个开源库,但它本身集成了市面上大部分服务商提供的语音识别方案,虽然大部分都是付费的(需要你自己去服务商购买然后输入 API KEY),但好在还是有 Google 家的方案还可以免费使用。
在所有会话的前面都加上 role=system 的指令,这一目的是让ChatGPT 的每一次回答都遵循 system 的指令,我目前设置的指令是:「Answer in concise language」,也就是用简洁的语言回答,如果不加这个指令,稍微长一点的话题就会反复说一些废话,这不利于对话的展开。这个指令在配置文件里是可更改的;
默认保留最近 3 次对话内容,ChatGPT API 默认并不会关联上下文的会话,这是与 Web 端最大的区别,如果想要关联上下文,那就只能把之前的会话内容一起发送,如果不限制一下保存的会话次数,那么越往后面消耗的 Token 就越恐怖;
我目前的调教方法是,普通聊天就保持默认配置不动;如果想要进行特殊的会话,比如让它当百科全书来回答问题,那么会话保留的条数可以更短,system 指令可以设置成:「尽可能详尽地回答」;如果想要练习英文口语,那么可以设置 system 指令为:「Play a English teacher, Point out grammatical errors and ask questions according to the context」;如果想要模拟面试,那么可以设置 system 指令为:「扮演一名 xx 岗位的面试官进行面试,简洁地回答和提问」。
在换了机场之后,我又入手了 Quantumult X。老实说,Quantumult X 这软件设计的交互逻辑真的有点奇葩……功能又复杂,如果不找教程的话完全无法通过自己的摸索来使用,而且稍微老一点的教程里的界面相比最新版 Quantumult X 界面都有不少改动,使用门槛比 Shadowrocket 真的高了很多。
两年前,我刚决定把博客迁移到 Hugo 时,因为找了许久都没有找到合适的主题,只好自己动手写了一个(项目地址:
Cirrus
);在随后的两年中博客便一直使用着这套主题,这期间倒是也陆续发现了其它一些还不错的,不过我却没有什么更换的念头,因为在自己动手写了一个主题之后明白了一个道理:只有自己设计的东西才能真正贴合自己的需求。两年后的现在,看着我写的第一个主题,心中虽感慨万千,却也愈看愈觉得它「稚嫩」与「不成熟」,不由得泛起重新设计一版主题的念头。
最近我们组要推出一个 DNS 防火墙产品——拦截黑名单域名并提供简单的查询分析功能。我主要是负责实现拦截功能,具体的工作是写一个插件让 CoreDNS 可以实现 DNS Sinkhole 的功能,也就是针对(特定的客户端)访问特定的域名返回错误的结果,同时将解析的结果输出到数据库保存下来以供后续分析。开发过程并不困难,反而是在开发完成后的测试阶段遇到了困难。
抽丝剥茧
如果只是对拦截功能的测试,还比较容易解决——无非是多写几个单元测试用例,可要对整个 CoreDNS 的解析、拦截功能进行测试就会麻烦不少:完整的 DNS 请求涉及到网络、IO、转发请求等各个方面,不再是通过测试用例就可以覆盖的。因此我最初的想法是在另一台服务器上把默认的 DNS 服务器改为运行 CoreDNS 的服务器地址,再在这台服务器上批量运行 gethostbyname 函数来发出域名的解析请求,每一条的解析请求背后都意味着一套完整的 DNS 解析流程,因此可以较好地覆盖 CoreDNS 解析、拦截功能的测试。
不过这却引来了另一个问题,之前提到过,我们还需要把 CoreDNS 解析的 DNS 记录保存下来供后续分析使用,如果所有的 DNS 请求来源都是在另一台设备上,那么所有 DNS 记录的源 IP 都会是同一个,虽然这对功能测试以及性能测试没有影响,但在产品的实际展示效果以及产品体验上会大打折扣。
因此,搞来一批 DNS 流量并想办法让流量流经 CoreDNS 的服务器并保持源 IP 不变,问题就能得到解决了。
声明:文中出现的所有 IP 协议谨代表 IPv4 协议,暂未进行 IPv6 协议测试
一些「头脑风暴」
思考了一阵,我冒出了一个有点不太靠谱想法:要是能把公司内网的 DNS 流量全都指向 CoreDNS 就好了——这对我们来说是最省事的,可显然是不符合实际的,先不说公司的其他部门会不会同意,我们是以测试 CoreDNS 为目的,而测试的过程是不稳定的:如果 CoreDNS 挂掉了那意味着全公司的员工都无法上网了…这损失我们显然承担不起。
于是我想到了另一个方法:既然不能改公司的原始 DNS 流量,那么我把原始流量通过 Tcpdump 导出成 Pcap 文件,然后把 Pcap 文件本身包含的 DNS 记录请求的地址改成 CoreDNS 服务器的地址,再通过类似 Tcpreplay 的手动重放不就可以了吗?
乍一看,这似乎是比较好的解决方法,然而在实际验证过程中发现此法也行不通:原因在于 Tcpreplay 只会把 Pcap 文件里的数据重放在对应的网卡上,而并不会实际在网卡上创建 TCP 连接。这也比较好理解,毕竟我在机器 A 上抓包与机器 B 通信数据生成的 Pcap 文件,再通过机器 C 上的 Tcpreplay 重放,这并不可能重新让机器 A 和机器 B 建立相同的连接。
特别需要注意的是,因为我们构造的 UDP 首部本身是包含着 sport 和 dport 的,因此我们在发送的时候的目标端口直接填写 0 即可。
CoreDNS 成功打印出如下日志,这意味构建 UDP 的首部也搞定了,离成功更近了一步:
[INFO] 127.0.0.1:10000 - 31895 "A IN baidu.com. udp 38 false 4096" NOERROR qr,rd,ra 88 0.070468417s
更近两步——IP 首部
虽然使用原始套接字能让我们成功伪造 UDP 首部,即更改源端口为任意数,但其实源端口的改动并不重要。我需要改动的是源地址,而源地址的改动则涉及到了 IP 协议的首部。
花费了一番功夫,发现了 IP_HDRINCL 这个原始套接字的选项,当创建的原始套接字是 IPPROTO_UDP 或者是 IPPROTO_TCP 时,此选项值默认填充为 0,此时待发送的数据包在流经 IP 层时会自动加上 IP 的首部,而当手动设置了此选项为 1 或者创建的原始套接字的类型是 IPPROTO_RAW 的时候,则不会自动加上 IP 的首部,也就是需要在发送的数据包上手动构造 IP 首部:
以下测试代码只在 Linux 下测试过,macOS 无法通过测试。
>>> records[0][IP]
>>> del records[0][IP].chksum # 因为 IP 的 payload 有所更改,因此 chksum 肯定有变化,可以直接删掉它
>>> records[0][IP].dst='10.6.3.33' # 更改 dst 为 CoreDNS 监听的地址, 但不能是 127.0.0.1
>>> RawIPSock = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket.IPPROTO_RAW)
>>> RawIPSock.sendto(raw(records[0][IP]), ('', 0)) # 因为包含了 IP 首部,因此目标 IP 地址也可不用填
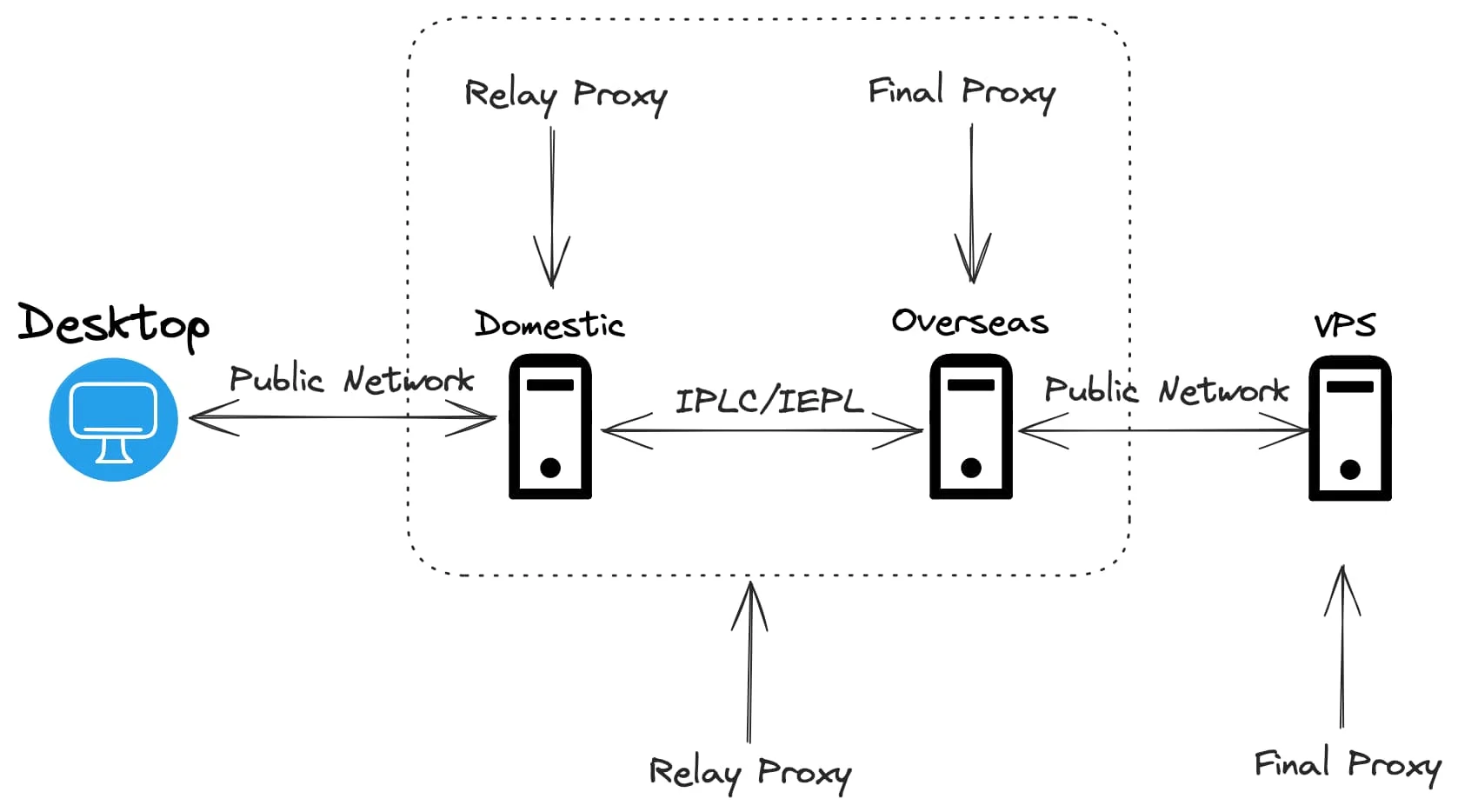
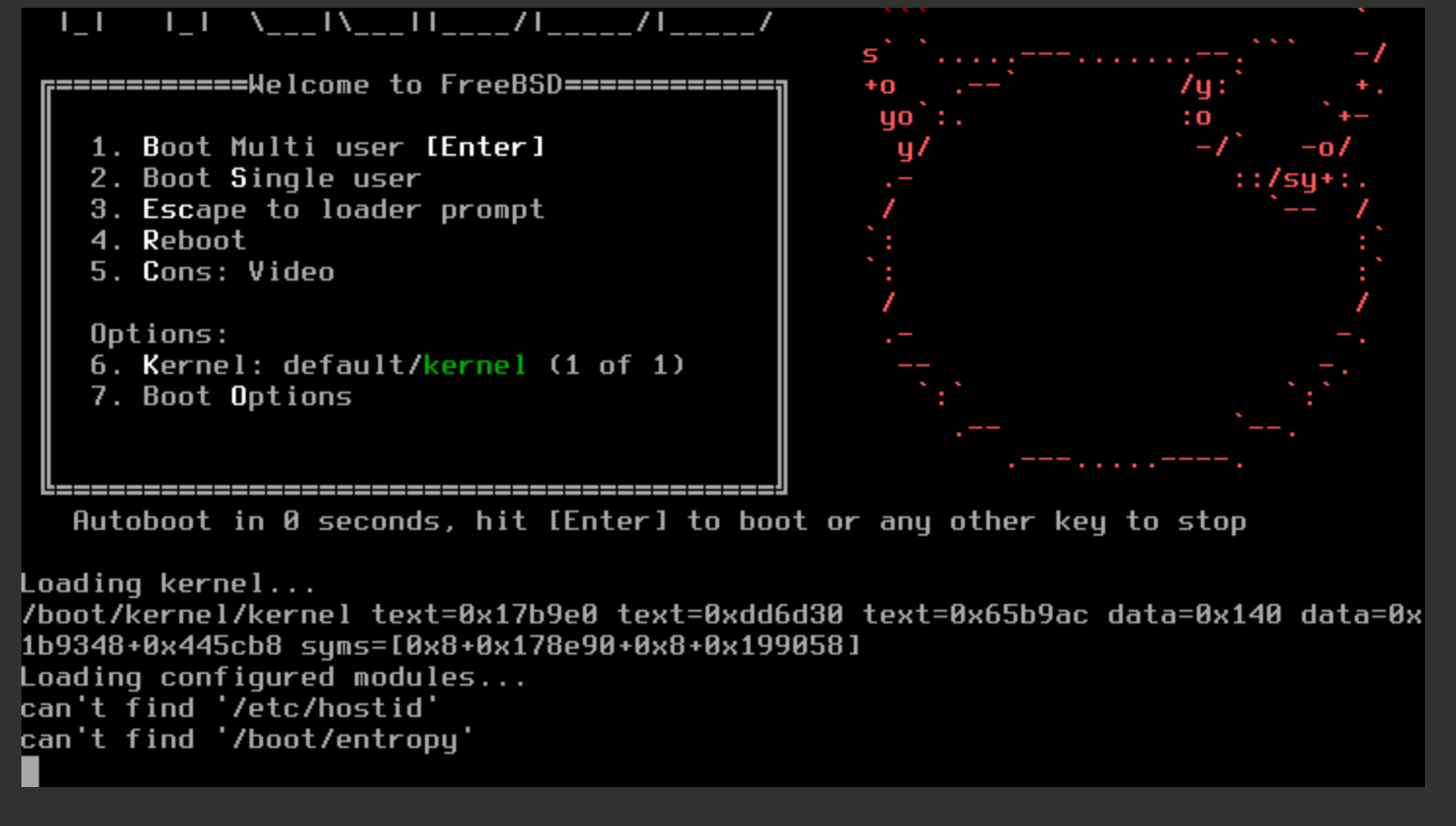
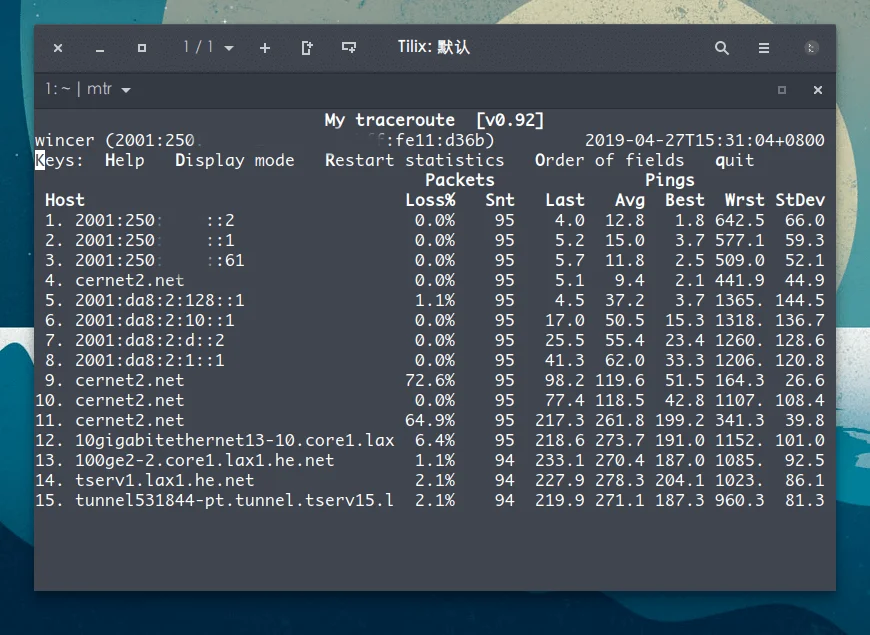
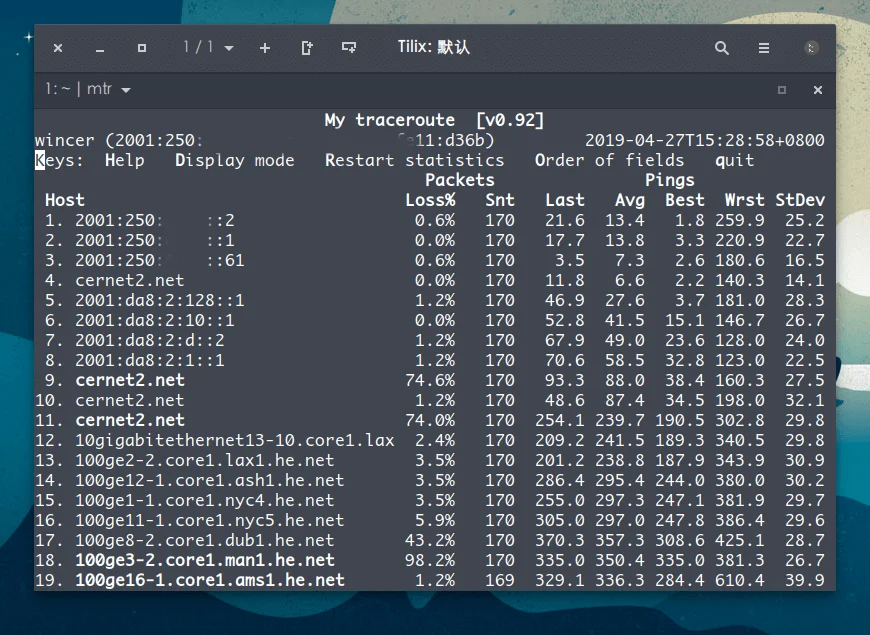
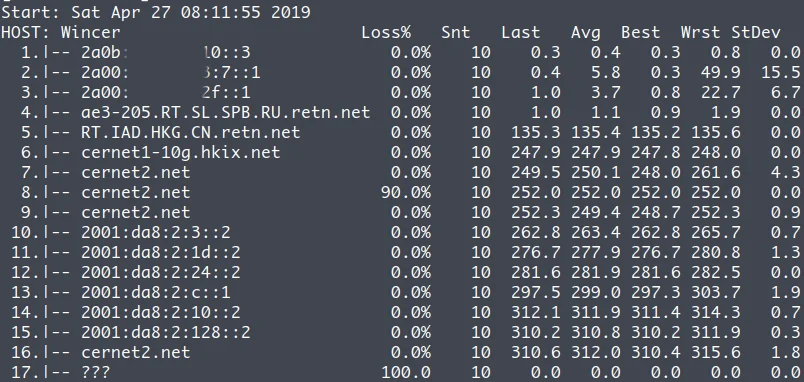
我一直是一个有些特立独行的人,因此对一些小众、非主流的事物有着偏好:通常不使用 Windows 作为电脑的操作系统,通常使用 Linux 或着 MacOS;使用 Markdown 来写文档,如果有精细的排版需求我会选择 LaTex,不使用 Word;Shell 的解释器我会使用 Fish 而不是 Zsh 或 Bash;浏览器也是 Firefox 的忠实用户;编程语言我也尽量往冷门的学,比如 Elixir……因此,在知道服务器的操作系统除了 Linux 还有 BSD 之后,使用 FreeBSD 作为服务器操作系统的念头便在心里埋下了,这埋下的念头之所以一直没有发芽,除了 FreeBSD 的软件相比 Linux 要少很多之外,更多的原因在于 FreeBSD 一直不支持 BBR 拥塞控制算法,索性,在最近的 FreeBSD 13 版本中,已经可以支持 BBR 了,于是我立刻订购了一台服务器开始了 FreeBSD 的折腾之路。
一波三折的安装
大多数的 VPS 服务提供商虽然在安装操作系统时提供了多种选择,但是大多都是 Linux 的不同发行版,换汤不换药。因此我费了不少力气才找到一家宣称支持 FreeBSD 的提供商。
我开始选择的是 San Jose 的机房(他们提供有 Dallas、Los Angeles、),因为实测 San Jose 机房的带宽我跑得最满,于是我就发了一个工单和客服说我需要安装 FreeBSD,请他们帮忙挂载一下 FreeBSD 13 的镜像。十几分钟后他们回复说成功挂载了,需要我登陆 VNC 继续后续的操作,当我登陆 VNC 后虽然进入了 FreeBSD 的引导界面,但是报错了:
过了几个小时,高级管理员回复了我,说他们正在探讨这个问题,并且怀疑是 San Jose 机房的内核、libvirt 版本不一致导致的,查验这个问题的修复结果需要重启,但由于机房存在大量的用户,所以这并不是一个很快就能解决的问题。于是他们提出可以为我免费迁移到他们确认可以安装 FreeBSD 的机房,一番测试后,我选择了 Seattle 的机房。
ext_if="em0"
IP_PUB="xx.xx.xx.xx"
nat on $ext_if from lo1:network to any -> ($ext_if)
# 下面配置可以将主机对应的端口直接转发到 jails 里
TROJAN_PORT="{443}"
rdr on $ext_if proto tcp from any to $IP_PUB port $TROJAN_PORT -> "10.6.0.3"
In the previous post, I introduced how to use Elixir to write a rate limit tool. After that, I was planning to integrate it with the
DIEM-API
. In this way, my API System doesn’t need to depend on Redis. However, DIEM-API is written in Golang, and I have not decided to re-write it in Elixir in the short term. Besides, I wrote a
search api
for my blog using Rust recently. Therefore, I need a cross-platform solution to address communication issues between Golang, Elixir and Rust.
Why not use other tools
Currently, there have been some ways to communicate between different processes (e.g. Pipe, Signal, Message Queue). But in fact, they have many limitations. Pipe and Signal require communication processes to be on the same machine. Message Queue and GRPC may be better solutions, but introducing new dependencies will complicate the system further.
TCP is another potential solution, but it is only able to transfer binary data. In other words, there is no simple way to decode data into typed parameters after receiving it from sender. REdis Serialization Protocol (RESP) is a request/response protocol over TCP, with various types of response (e.g. status reply, error reply, integer reply, bulk reply) but only one parameter type (string). However, function calls have only one response type but various types of parameters, which is the opposite to RESP. Therefore, RESP can not be used for inter-process calls.
Another way I tried is using separators between multiple parameters, which also introduces two new problems:
Performance: splitting and casting string has penalty on performance; (
benchmarks
)
Accuracy: if the parameter contains characters that are the same as the separator, it is not able to distinguish them.
Although these ideas don’t work, they gave me some inspiration. I decided to transfer the length of parameters and the typed parameter together.
This is Type-Length-Value (hereinafter referred to as TLV).
Introduce TLV
TLV is an encoding scheme. It must be based on one communication protocol, like: TCP, UDP or Unix Domain Socket.
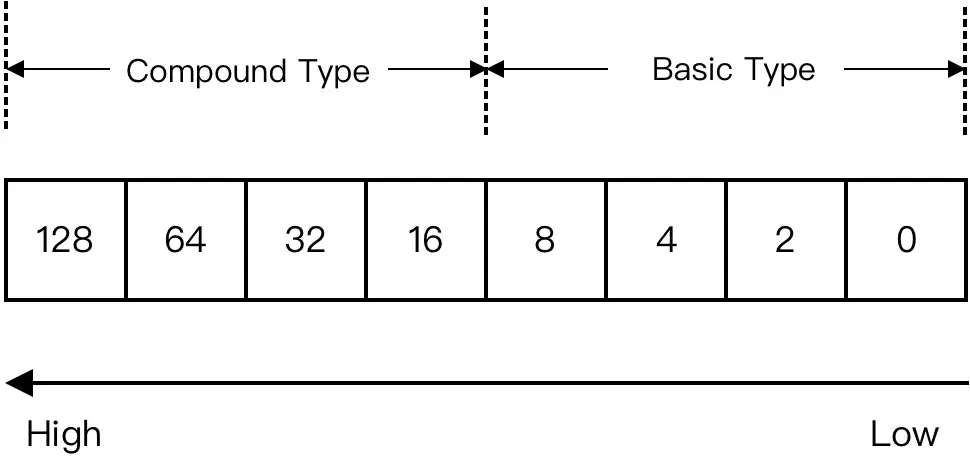
A TLV element should consist of three parts (Figure 1):
Type. It represents raw value’s type before encoding. Usually, we define an enumeration for these types. We use ones-digits to represent basic types, such as 0x1 for String, 0x2 for Integer, 0x3 for Float, etc.. We use tens-digits to represent compound types, such as 0x1[any digit] for List, 0x2[any digit] for Hash. The enumeration can also contain types which are unique to programming language, such as Atom type in Elixir.
Length. It represents raw value’s byte length after encoding. However, it is useless for Integer and Float, because these types have fixed byte length (usually 8 bytes) after encoding.
Value. It represents the raw value’s bytes after encoding. It can also nest in another TLV element when Type is a List or Hash (Figure 2). We can decode this part recursively.
Implementation Details
In this section, I will introduce how I implemented the encoding and decoding of TLV elements.
Type
This part should occupy 1 byte / 8 bits. Lower 4 bits represent the basic type, which can cover 16 basic types. Higher 4 bits represent compound type, which can also cover 16 compound types:
If raw value is a basic type, then higher 4 bits should all be 0.
If raw value is a compound type, we should only use higher 4 bits, regardless of lower 4 bits.
Length
This part should occupy 4 bytes / 32 bits. It can represent a value whose length up to 2 ** 32 bytes(about 4 GB).
For Integer and Float, higher 3 bytes are 0s, lowest byte is 8, which means Integer and Float can be represented by 8 bytes.
For String and compound type, we need to calculate the length of value first, and then convert the length to bytes.
Besides, we can use binary.BigEndian.PutUint32 function for Golang, use <<int_value::integer-32>> for Elixir, use .to_be_bytes() for Rust.
Value
This part should occupy at least 8 bytes / 64 bit (except Bool).
For Integer, we can use the above method to convert it to bytes; For Float, we can use math.Float64bits to convert it to int64, then convert int64 to bytes. For Golang, Rust and Elixir, String is a byte array (char array), which can be converted to bytes directly.
If there are nested elements, they must be encoded first, which can be processed recursively (in Elixir) or iteratively (in Rust and Golang). Same as decoding. And we should consider the case where a List element contains different types, which is allowed for dynamically typed languages (Python, Elixir) and some weakly typed languages (Golang can use []interface{}), although using reflection will cause more overhead.
Appendix
Benchmarks (Golang)
I wrote some bench tests for TLV (encoding, decoding) and Separator + strings (mentioned in the
previous section
):
辞职后的两个月里没少被家里人数落:哎呀,你怎么还不去找工作啊;总在家待着怎么行啊,你不知道空闲时间越久就越找不到工作啊(还好有女朋友一直在身边鼓励我)……总之,无论是处于父母的唠叨还是我自己本身的计划,六月初的时候,我开始步入找工作的阶段了。首先是在 BOSS 直聘找了两家中型公司投了一下,结果都是已读未回,在这之后我就干脆放弃了招聘软件这条路,开始转向官网投递。
在这之后就是现在的公司了,也是在 V2EX 上翻到的招聘贴,不过录取的经历却颇有些一波三折:一面发挥不是特别好,有几个偏底层的问题没有回答上来,其中有的是因为没有 GET 到面试官的点,有的是因为确实不会;所以之后几天得到的回复是没有通过面试,谁知过了两周之后面试官又说没有找到更合适的了,想问问我愿不愿意继续后面的流程……于是,在八月初时,终于结束了在家待业四个多月的日子,开始了一段新的旅程。
从大一暑假开始,我便一直使用 Linux 作为日常所用的系统,这三年要说我用 Linux 如何顺心,那绝对是鬼话;可要说我使用得特别难受,那也不至于。因为它的确提升了我的开发体验和编程技能。它的优点我很喜欢、它的缺点我一开始就知道并能接受——这便是我能坚持使用 Linux 三年的原因。
虽然坚持使用了这么久,可我还是要说一句 Linux 作为日常使用的系统真的很不方便,而不方便就会想要去折腾,折腾来折腾去发现时间都浪费了,它还是老样子;可使用 Windows 吧,看着丑哭的字体渲染和残废的命令行工具,感觉自己写代码都没什么动力了,所以当我第一次见到 macOS 时,我在心里就默默地种草了。
种草容易拔草难啊,这一拔就拔了三年。
说起来是有些奇怪,明明我这么想用 macOS,为什么不直接买一台 Mac 呢,其实是因为我对 Windows 还有需要:闲暇时我也会打打游戏,而购置一台用于打游戏顺畅的 Mac,恐怕就只能从 (i)Mac Pro 起步了——我肯定是不会买的。于是,我选择了黑苹果。
配置单
按照 Tonymacx86 的说法,黑苹果最好选用八代或九代的 Intel CPU ➕ AMD 的显卡配合 Z390 芯片的主板。
#######################################################
# SSDT Time #
#######################################################
Current DSDT: None
1. FixHPET - Patch out IRQ Conflicts
2. FakeEC - OS-aware Fake EC
3. PluginType - Sets plugin-type = 1 on CPU0/PR00
4. Dump DSDT - Automatically dump the system DSDT
D. Select DSDT or origin folder
Q. Quit
Please make a selection: 4
DSDT.aml 会被提取到脚本目录的 Results 目录下。
注入原生电源管理
SSDT-PLUG.aml(名字并无限制) 补丁是用于支持原生的 CPU 电源管理。使用 SSDTTime 进行生成:
运行 ./SSDTTime.command(SSDTTime.bat)
#####################################################
# SSDT Time #
#####################################################
Current DSDT: None
1. FixHPET - Patch out IRQ Conflicts
2. FakeEC - OS-aware Fake EC
3. PluginType - Sets plugin-type = 1 on CPU0/PR00
D. Select DSDT or origin folder
Q. Quit
Please make a selection:
输入 「3」后,将 DSDT.aml 拖入当前终端窗口,并 Enter :
#####################################################
# Select DSDT #
#####################################################
M. Main
Q. Quit
Please drag and drop a DSDT.aml or origin folder here:
SSDT-PLUG.aml 会自动生成在 Results 文件夹:
#####################################################
# Plugin Type #
#####################################################
Determining CPU name scheme...
- Found PR00
Determining CPU parent name scheme...
- Found _SB_
Creating SSDT-PLUG...
Compiling...
Done.
Press [enter] to return...
由于 OpenCore 的配置比较追求轻量化,因此一些人在将 Clover 换成 OpenCore 的时候可能会出现一些 USB 设备失灵的问题:鼠标和键盘的指示灯都没有亮,显示没有通电。
这里可以使用 SSDT-USBX.aml 来解决这个问题,但是并不推荐,原因之前也说过了,ACPI 的补丁对 Windows 也是适用的,而 Windows 压根不需要这个 USBX 的补丁,并且这个补丁有一个 bug(feature?):它会将所有的 USB 设备识别成内置的接口,即使你插入的是 U 盘。一旦系统将 U 盘识别成内置的硬盘,就无法使用 Mac 自带的「启动转换助理」来刻录 Windwos 系统盘了(这一点下一节会详细讲)。
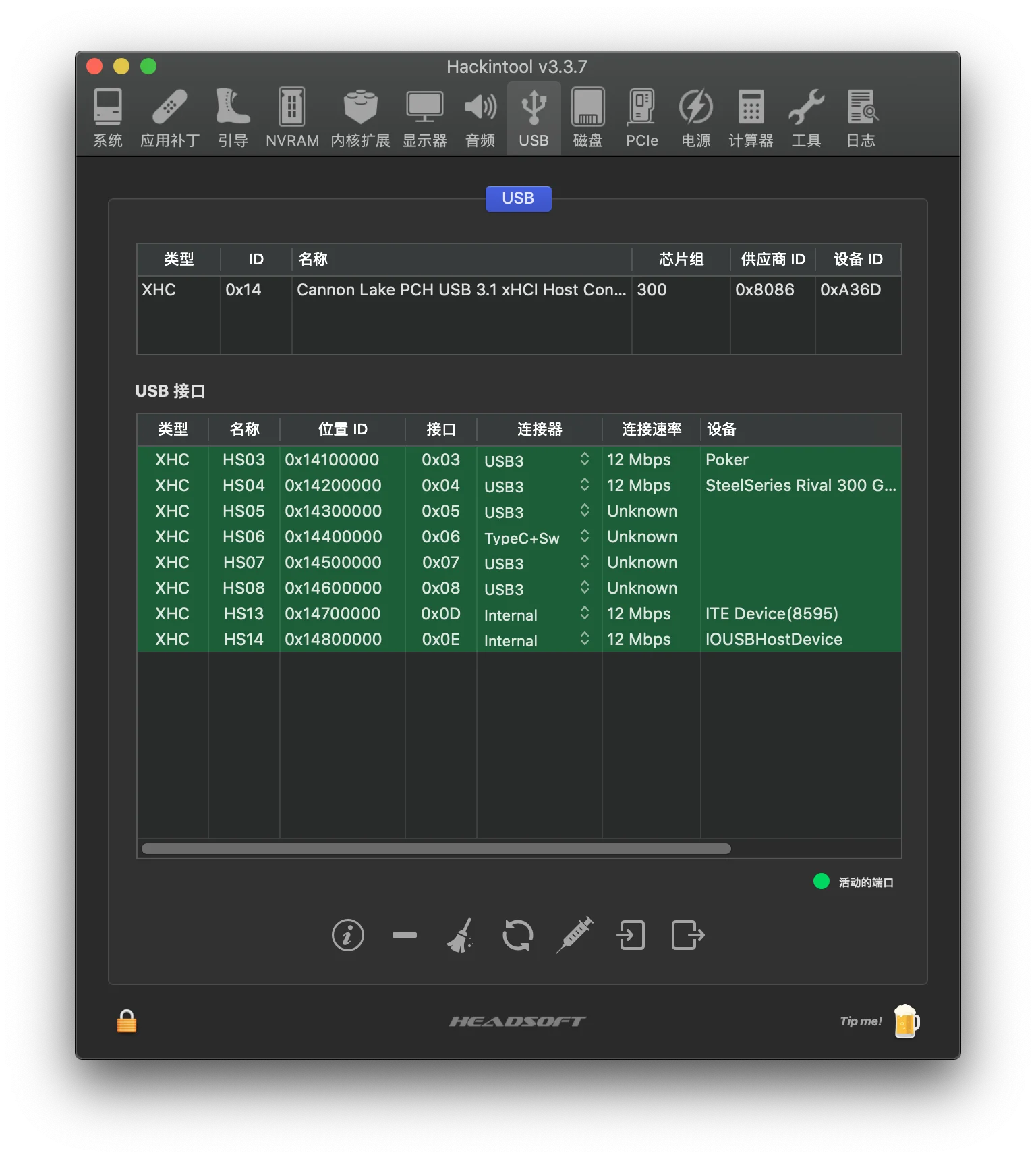
除了使用 ACPI 补丁之外,还可以使用 macOS 内核扩展(kext)来解决这个问题:首先使用 USBInjectAll.kext 来设置所有 USB 接口为外置 USB,确保系统能正常使用;然后打开 Hackintool 的 USB 选项卡,随后将主板的所有 USB 逐个插一遍,将非活动端口删掉,并使用连接器定制每个端口的类型。
几年前,软件的架构都是单体式(Monolithic)的:即使一个 Web 系统的大多数模块在业务上并不是紧密相连的,它们仍然会运行在一个操作系统级别的进程当中(如今大把的软件仍然是这样的架构),这也就意味着单独改动某一个模块,在部署时必须重新将整个系统都打包一遍。并且由于大部分单体式的软件在架构层面缺少优化,在打包部署时简直就像是一场灾难,而作为开发人员最难受的是明明有办法阻止灾难发生但却无能为力。
比如我的前公司:先把 Web 应用打一个包(包含各种 pip 的库),再把底层依赖打一个包(Elasticsearch、PostrgeSQL、Nginx,以及各种 rpm 包),这两步下来,包的大小已经直逼 3 个 G 了,每次打包部署的流程差不多都要花费两三个小时,而且有时候还安装失败。
所谓「工欲善其事,必先利其器」,在学习之前,首先得要把环境搭好,上网看了一圈之后,决定装一个 Linux 系统(与 Windows 共存)专门用于编程,当时我对操作系统完全是一窍不通,导致在装完 Linux 系统之后重启直接回到了 Windows,百度后尝试了许多方法(比如:把 UEFI 模式改成 Legacy啊、用什么 Boot 编辑器啊),但都没什么卵用,逼得我甚至冒出了将 Windows 整个格式化掉的想法。
最后还是在暑假期间解决了,还在简书写了一篇教程(一年之后居然有两万多浏览量),成功安装好双系统之后,我又开始像高中折腾安卓一样开始折腾 Linux 发行版的各种美化(真是死性不改😅):Terminal 的美化,状态栏、主题图标的美化等等,原定好的学习编程计划也搁置了。如果时光可以倒流的话我一定会告诉当时的自己:「不要再花时间在这些没卵用的美化上了!快点学习吧!」,不过当时的我也肯定听不进去,毕竟颜值才是第一生产力~
得益于博客的搭建,我的知识面被扩充了不少,也了解到了 SICP(Structure and Interpretation of Computer Programs)这本神作,在暑假前,我在图书馆借阅了这本书,花了一整个暑假的时间,却仍只读完了半本(读完了前两章,做完了
习题
),该怎么形容我那两个月的感受呢,感觉自己的编程世界观受到了冲击(也是在阅读第一章后,我彻底明白了递归与迭代的区别),感觉自己的脑回路好像都被重构了一样。
在看完了 MIT 6.0001 后,如果你想成为一名更好的程序员,并打算继续深入,那么看看 SICP 这本书吧,不会错的。
大三
大三时,逃课开始变成了家常便饭(尤其是离散数学,但是我一学期没怎么去上过,期末反而还考了满分),不过数据库这门课我倒是每次都去上了(只是差不多每堂课都会迟到😅),因为授课老师就是上学期的操作系统的老师,对她印象还蛮好的(不过我现在还很奇怪的一点是为什么老师要教 SQL Server 而不是 MySQL 或者 PostgreSQL)。数据库课程分为理论课和上机课,由于上机课和理论课不在同一所教学楼,于是在理论课下课时便会和几个同学绕一大圈,逛逛校园,再慢慢地抵达上机课的教室,好在老师也不会说些什么。
当时还有一门课是软件工程,遗憾的是软件工程的重要性是我在工作之后才明白,因此当时这门课我并没有去几次,而且老师一开始就说了这门课的考核标准:交一个系统上来就行了。于是断断续续花了两个月时间,读完了狗书(Flask Web开发:基于 Python 的 Web 应用开发实战),照着书上面的代码自己敲了一遍,也算清楚了 Python 的开发流程。
除了了解 Python 开发之外,当时还针对 NexT 主题做了很多定制化操作,也借此学习了一下 JavaScript 中是如何使用 Template 的。
def foo(n):
def bar(i):
n = n + i
return n
return bar
在 foo 内部的 bar 函数中,n = n + i 语句会在当前词法作用域新建一个变量 n(当前作用域不存在 n 而且有「=」符号),因此这个写法是错误的,运行会得到 UnboundLocalError 的错误,除非在 bar 函数中显式声明:nonlocal n,表示 n 使用上一层词法作用域的值。
那么为什么书中的实现没有声明 nonlocal 也可以呢?注意我刚刚提到的,Python 虽然不支持对词法变量的「重新赋值」,但是支持对已存在的词法变量「修改」:对于 s 来说,s[0] += i 这个操作,并没有把 s 重新赋值,而只是把 s 的其中一个元素修改了,换句话说 s 本身的地址是没有变的:
iex(6)> foo = fn n ->
fn i ->
n = n + i
end
end
warning: variable "n" is unused
iex(7)> f = foo.(7)
iex(8)> f.(8)
15 # 首次调用,符合预期
iex(9)> f.(8)
15 # 这里我们期待值为 23
但这种写法得到了不符合我们预期的行为,它同样会在内部匿名函数的词法作用域中添加 n 变量(由于 n 没有使用,所以解释器报 warning 了),并不会对外部作用域的 n 变量进行修改。且 Elixir 并没有 Python 那样的 trick(使用 list、dict 等可变类型),毕竟 Elixir 里的数据是不可变的(无论是什么数据类型)。
花了差不多俩月时间(中间包含着春节),捣鼓了一篇万余字的论文出来(论文是用 Latex 写的 ,为了让排版符合学校规定,调整了好久,如果不是因为这点,应该一个月就差不多了),满心欢喜地发给老师,结果老师压根就没看:「明天打印一份出来我再看,电子版与打印版的格式会不一样」,我盯着屏幕上的 PDF 文件陷入了沉思,难道 PDF 电子版打印出来会不一样嘛?
直到前几天
WakaTime
发邮件过来说已经两周时间没收到我的 Code Activity 了,问是不是插件出了什么问题:「Please
reinstall the plugin
to continue using the WakaTime dashboard」。其实并不是插件出了什么问题,而是我真的两周没有编程了(笑。
Python 作为一种具备多种编程范式的语言,面向对象自然也是它所具备的范式之一;而继承,作为面向对象程序设计的三大特性之一,其重要性也是不容忽视的。尤其这一特性在支持面向对象范式的语言里还有着不同的规则,如:C++ 同时支持普通继承和虚继承;Java 则是将其它语言中的 class 细分为 class 和 interface;还有 Python,「无痛地」支持多重继承。
首先看看 C++ 是怎么解决第一个问题的:C++ 在遇到这种情况时,最顶层的基类(A)会被创建两次,虽然可以通过将 A 设置为 B、C 的虚基类来解决,但这种虚继承是有副作用的:不只是在获取成员会更慢、占用内存更多,在和虚函数一起出现时会更难以理解:当 A、B、C、D 中都有一个虚函数 f 时, D::f 内部调用了 B::f 和 C::f;B::f和C::f内部都调用了A::f,于是 A::f就被调用了两次。当然也不是没有办法解决,
Template Parameters as Base Classes
就是 C++ 之父专门用于解决这个问题所开发的技术。
第二个问题:如果这里的 B 和 C 同时实现了 hello 方法,同时 D 中没有实现 hello 方法,那么在调用 d.hello()(d 为 D 的 instance) 的时候会调用哪一个?编译器对于这种 Ambiguous base classes 的情况会直接报错,解决方法也简单粗暴,你必须显式指定 d.B::hello() 来调用 B 中的 hello。虽然以上两个问题在 C++ 中都解决的并不好,但也总归是解决了。下面来说说 Java。
Java
Java 之父觉得 C++ 太难用了,于是他决定创造一门语言来取代 C++,这门语言需要保留 C++ 的优点,但又需要把 C++ 中较为混乱、复杂、危险的部分剔除(其中就包括了多重继承),于是,Java 就在这样的理念里诞生了。在 Java 诞生之初,对多重继承的支持少的可怜:一个 class 仅可继承(实现)多个 interface。本来是挺好的,但是在 Java 8 中为 interface 中的方法引入了 default 关键字,这就让 interface 里定义的方法可以有方法体了。
class A:
def hello(self):
print("Hello from A")
class B(A):
def hello(self):
print("Hello from B")
super().hello()
class C(A):
def hello(self):
print("Hello from C")
super().hello()
class D(B, C):
def hello(self):
print("Hello from D")
super().hello()
>>> d = D()
>>> d.hello()
Hello from D
Hello from B
Hello from C
Hello from A
在 D 中遇到的 super() 会沿着 D 的 MRO 依次向上寻找超类中的 hello 方法并执行,即依次执行 D -> B -> C -> A 这个顺序。
那么为什么 Java 或 C++ 无法通过这种写法解决呢,原因在于 Java 的 super 在多重继承中必须指定父类是哪一个,因为编译器是无法获知你想要运行的是哪一个父类的方法。而一旦指定了父类(B),那么与这个父类同时继承的另一个父类(C)你也必须要指定,而这两个父类又具有相同的更高层次的父类(A),所以就导致了最顶层的父类(A)中的方法被调用了两次。
下面来具体说说 Python 中的 super 类。
super 的作用
在 Python 中某 class 使用了 super() 后,super 即会沿着最初调用 super() 的那个 class 的 MRO 向上寻找超类:
关于我 21 岁的谈人生瞎扯淡就在这里告一段落了。确实,我没有像去年那样在全文中都很明确的表达出一个观点并以此作为我接下来一年生活的座右铭。反而是给了一个模棱两可的答案。但我想,相比去年,这个答案确实更好了——因为得出这个答案我思考得更全面了。或许我需要像阿甘一样,连续奔跑三年才知道自己为什么要奔跑。谁知道呢,也许我明天就想明白了,Life was like a box of chocolates. You never know what you’re gonna get(译文:人呐,就都不知道(命运),自己就不可以预料)。
用杨绛答复别人回信作为结尾吧:
你们这些年轻人啊! too young too simple, sometimes naive!你们啊,还是要提高自己的知识水平。
八个月前,我把建站之初就使用的 NexT 主题换成了 Material 主题,依稀还记得当时告诉自己:以后就好好写文章,绝对不再耗费时间在这没啥价值的事情上(让你立 Flag!后悔了吧?)。时隔半年多,如今发现对我来说好像不折腾比折腾还要难一些,原因嘛,自然是新鲜感与强迫症在作祟,这次折腾的起因就在于新鲜感——我看上了一个主题。
优点与缺点
这次更换的主题是
inside
,该主题相较于其它 hexo 主题的特殊之处就在于它的本质是采用 Angular 编写的 SPA(single page web application,单页应用程序)。优点就在于每次点击不同的链接只产生一个 HTTP 请求,返回的是一个 .json 文件,包含该页面的内容(内容已在 hexo g 时已经转成 HTML 格式了),而一旦接收到 .json 文件后,就会将文件的内容通过 innerHTML 属性嵌入页面。
而缺点在于相较于普通的页面,可能对 SEO 不那么友好。因为阻止页面呈现的 JavaScript 可能会对用户体验造成不好的影响,而我为此在额外方面做了补足:添加了 27 个 <meta> 标签,用 Google Chrome 测试 SEO 那一项拿了 89 分,应该还算不错了(拿不到满分是因为部分字体小于 16px)。
原主题的默认字体大小是 14px,我将正文修改成了 16px,代码字体修改为了 15px,这应该会比原主题看起来舒服一点。并且我移除了主题额外加载的字体文件,而纯粹改用 font-family 来呈现。参考了
fonts.css
。我能吞下玻璃而不伤身体。The quick brown fox jumps over the lazy dog.
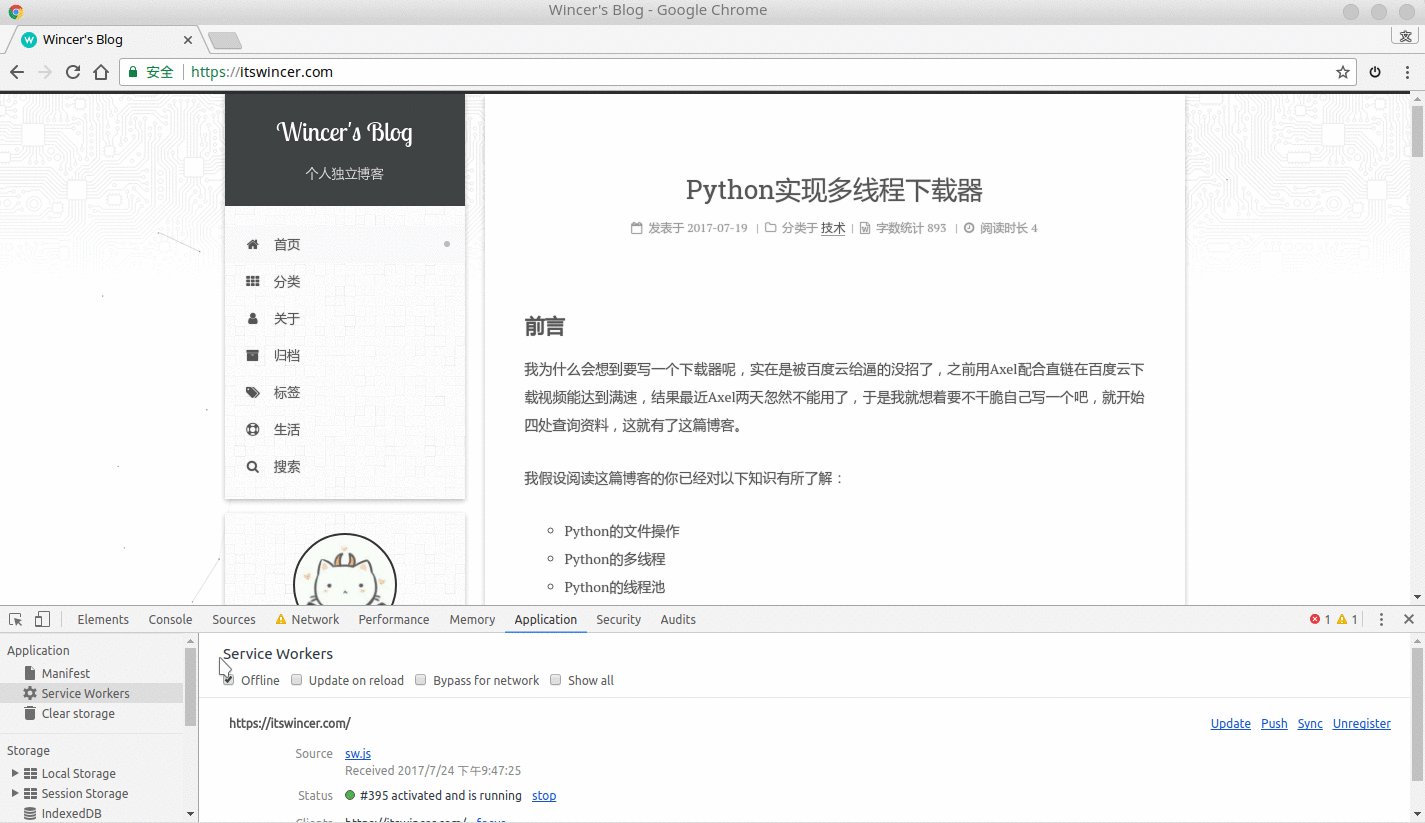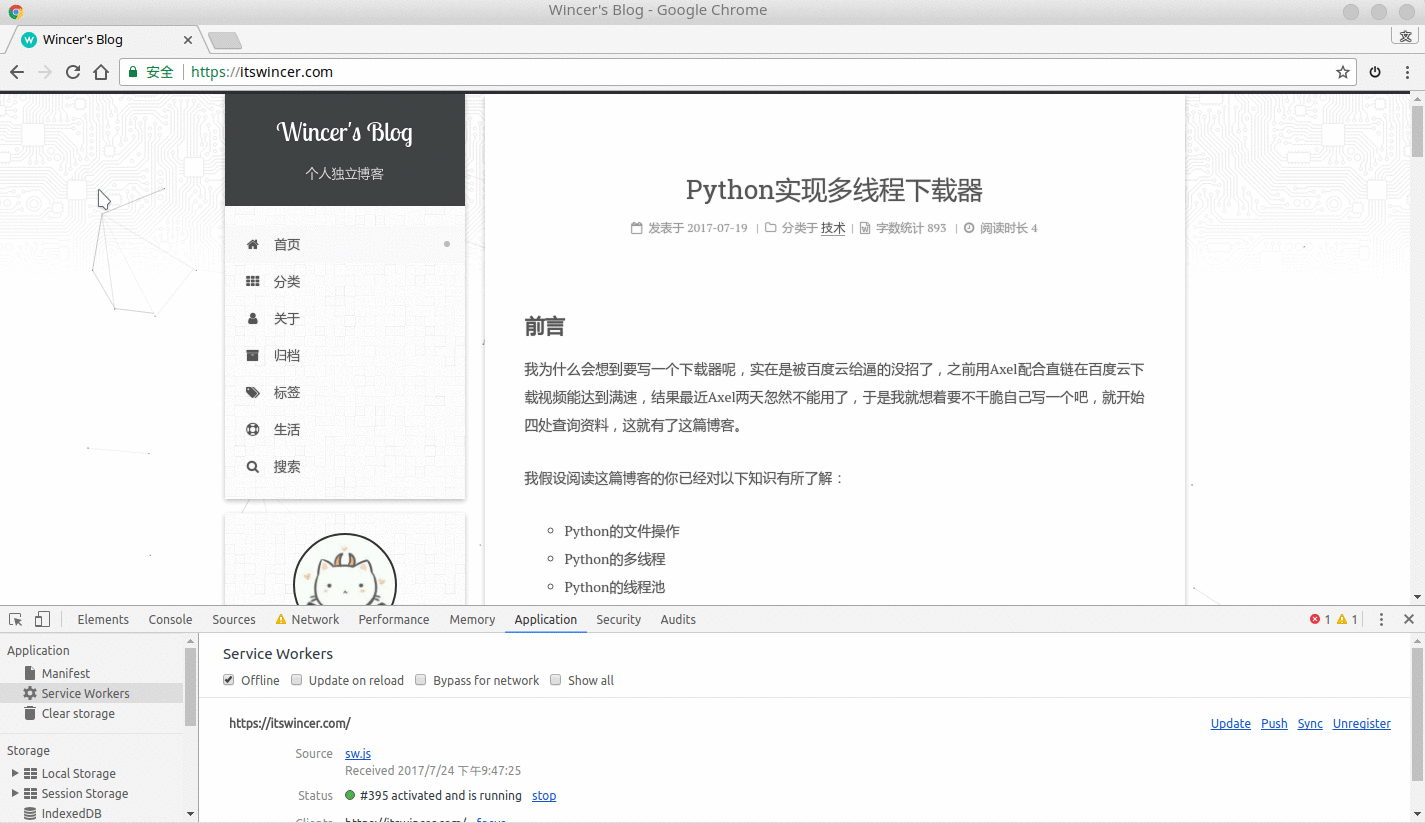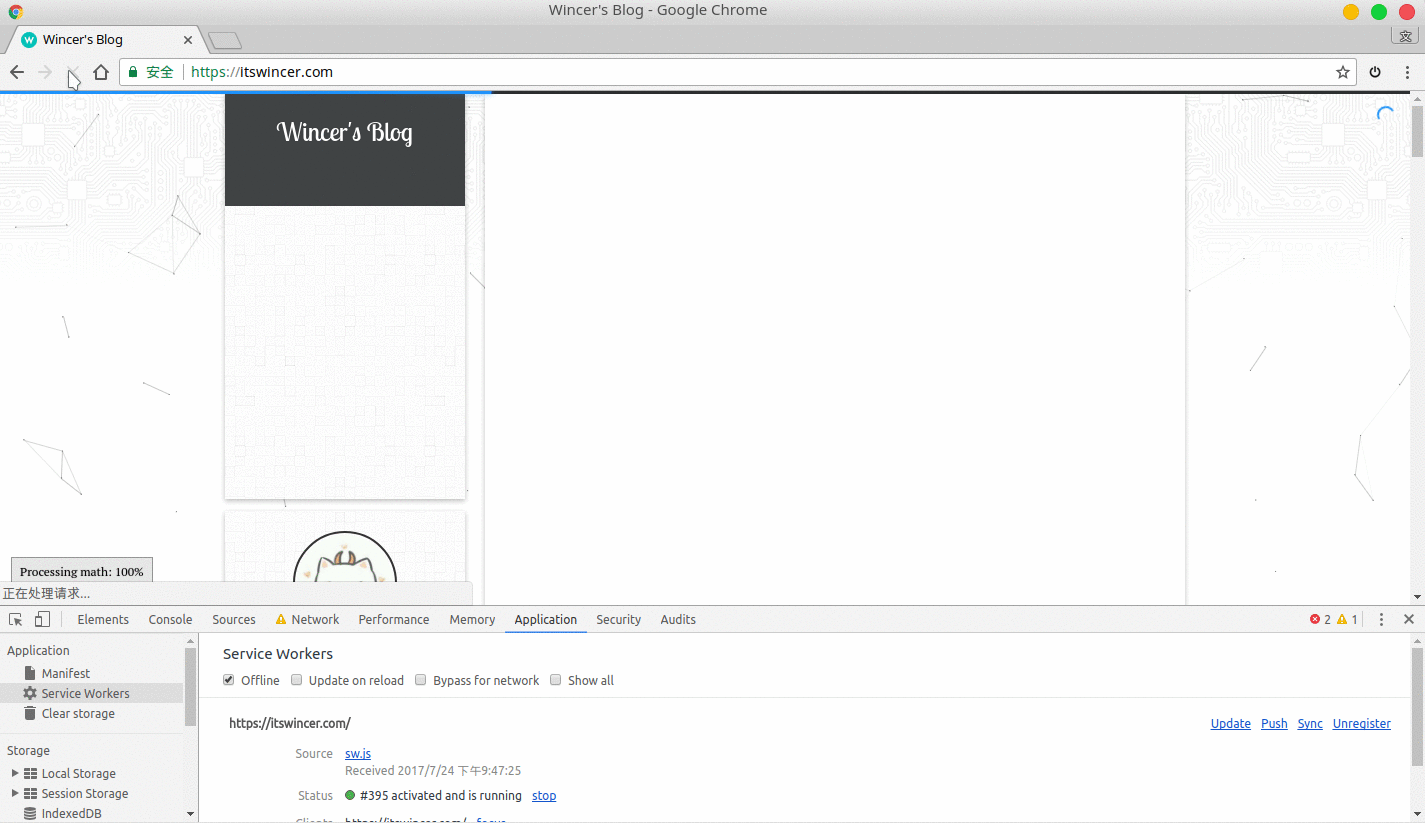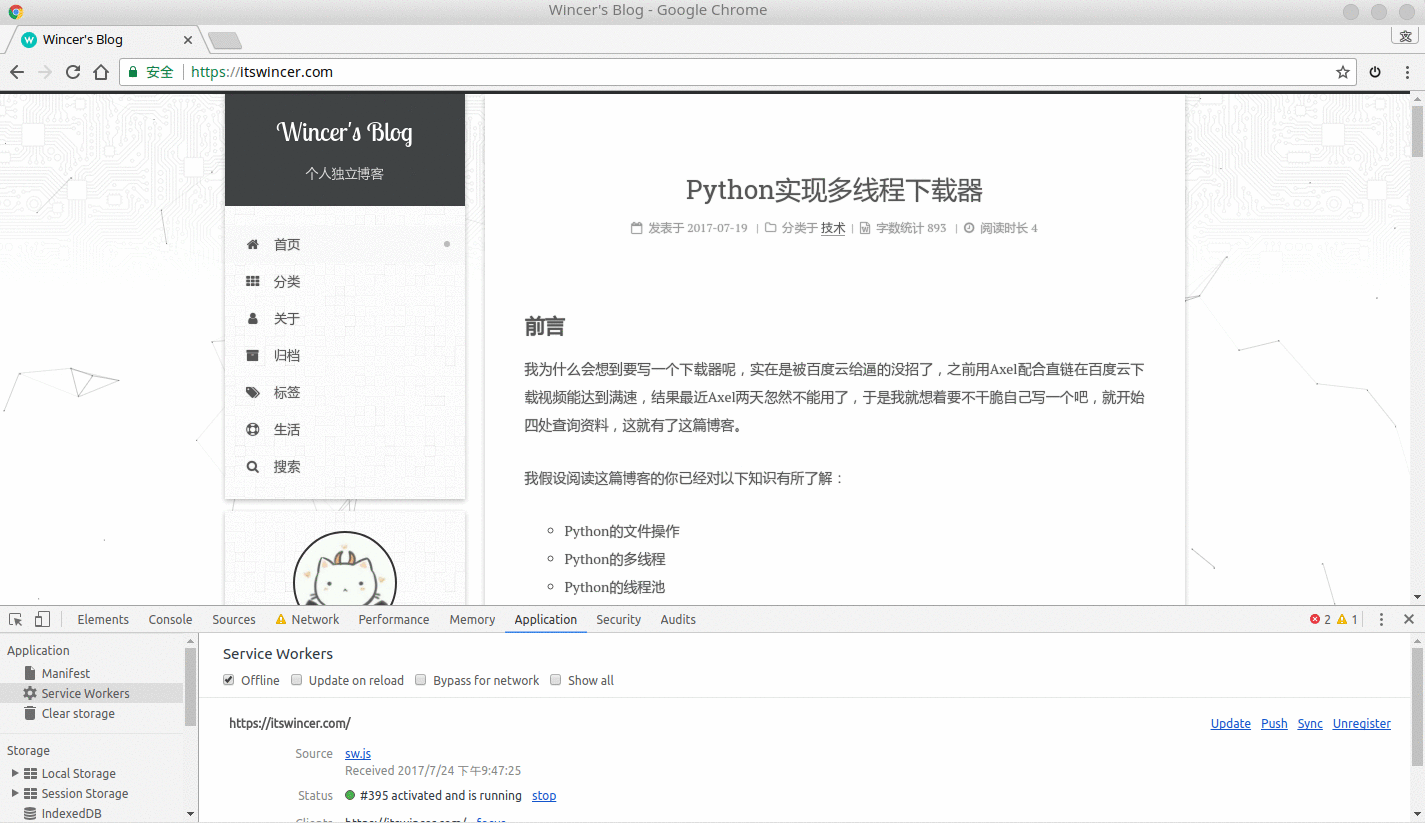
Service Worker
原主题不带 Service Worker 功能,但我还是为我的博客注册了 Service Worker 功能。
from array import array
from reprlib import repr
ints = array('l', (i for i in range(10**7)))
>>> repr(ints)
"array('l', [0, 1, 2, 3, 4, ...])"
# write to file
with open('ints.bin', 'wb') as fp:
ints.tofile(fp)
ints2 = array('l')
# read from file
with open('ints.bin', 'wb') as fp:
ints2.fromfile(fp, 10**7)
curl http://0.0.0.0:8888
Hello World
curl http://0.0.0.0:8889/\?test
Hello World
curl -X OPTIONS http://0.0.0.0:8889/\?test
Hello World
curl -X POST http://0.0.0.0:8889/\?test\¶m\=block
Hello World
我的博客在建站后不久就使用了
Travis CI
自动部署服务,即我只需要将修改的源码推送至 GitHub,Travis CI 会自动将我提交的代码拉取,在 Travis CI 端生成静态文件后,同步至我的服务器,这样可以减少一些麻烦的步骤:可以直接在 GitHub 端修改代码;不用等待生成静态文件、压缩静态文件的时间。
点击 CircleCI 个人主页的 JOBS 菜单项,随后点击仓库名称右边的齿轮按钮 -> 点击 SSH Permissions -> 点击蓝色的 Add SSH Key 按钮,将私钥(看清楚了,是私钥)粘贴进去(超级良心有木有啊,比 Travis CI 将私钥加密上传这种土办法不知道高到哪里去了)。
添加 IP 至 known_hosts
添加 SSH 密钥后,还需要将服务器的 IP 添加至 known_hosts 列表,否则每次部署的时候都会让你确认以下消息:
The authenticity of host '××.×××.×××.×××' can't be established.
ECDSA key fingerprint is SHA256:7hkfahfla8VeiuyF/TLHKfhakgcJ0sHjaLxDyIKlfhak9fuaofoa.
Are you sure you want to continue connecting (yes/no)?
同 Travis CI 类似,CircleCI 在运行的过程中也是不接受命令行输入的(当然运行完成后就更不行了),所以我们需要提前将 IP 写入 known_hosts(在 CircleCI 中如何做?继续往后看):
a = dict(one=1, two=2, three=3)
b = {'one': 1, 'two': 2, 'three': 3}
c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
d = dict([('two', 2), ('one', 1), ('three', 3)])
e = dict({'three': 3, 'one': 1, 'two': 2})
>>> a == b == c == d == e
True
from collections import namedtuple
ID = namedtuple('ID', 'name age')
me = ID('wincer', 20)
>>> me.name
'wincer'
ID = namedtuple('ID', '(1, 0) age')
ValueError: Type names and field names must be valid identifiers: '(1'
# 创建 nextcloud 数据库
CREATE DATABASE nextcloud CHARACTER SET = utf8 COLLATE = utf8_general_ci;
# 创建 nextcloud 的用户
CREATE USER nextcloud IDENTIFIED BY 'admin123';
# 赋予对数据库所有的权限
GRANT ALL ON nextcloud.* TO nextcloud;
var url1 = "https://lab.itswincer.com/jsonp/without-callback.js";
var url2 = "https://lab.itswincer.com/jsonp/with-callback.js";
function foo(data) {
alert(`Hi, I am ${data.name}`);
}
var script = document.createElement('script');
script.setAttribute('src', url1);
document.body.appendChild(script);
script.setAttribute('src', url2);
document.body.appendChild(script);
它们(指某些语言)的内核设计得并非很好,但是却有着无数强大的函数库,可以用来解决特定的问题。(你可以想象一辆本身性能很差的小汽车,车顶却绑着一个飞机发动机。)有一些很琐碎、很普遍的问题,程序员本来要花大量时间来解决,但是有了这些函数库以后,解决起来就变得很容易,所以这些库本身可能比核心的语言还要重要。所以,这些奇特组合的语言还是蛮有用的,一时间变得相当流行。车顶上绑着飞机发动机的小车也许真能开,只要你不尝试拐弯,可能就不会出问题。(内心 OS:我可没有针对 C++ 😏)
这本书算是我从去年 7 月以来看完的第一本书了(《计算机程序的构造和解释》这本书太难了,看了前两章就没时间看,到还书的日期了),主要也在于作者 Paul Graham 的行文十分流畅,阮一峰的翻译也很到位,没有什么阅读障碍,还有「读至好几处都有一拍大腿,哎呀妈呀我也是这么想的啊」的想法,读完之后,思想也似乎豁然开朗了些。
def get_info(url):
movie = {}
proxies = {'https': "socks5://127.0.0.1:1080"}
info = get(url, cookies=read_cookie(), proxies=proxies).text
soup = BeautifulSoup(info)
try:
# get movie name
name = soup.find(property='v:itemreviewed').get_text()
movie['name'] = name.split(' ')[0]
# get movie year
year = soup.find(class_='year').get_text()
movie['year'] = year[1:-1]
# get movie info
info = soup.find(id='info').get_text().replace(' ', '').split('\n')
info = [x for x in info if x is not '']
for item in info:
if '导演:' in item:
movie['director'] = item[3:].split('/')
if '主演:' in item:
movie['actors'] = item[3:].split('/')
if '类型:' in item:
movie['type'] = item[3:].split('/')
if '国家/地区:' in item:
movie['region'] = item[8:].split('/')
if '语言:' in item:
movie['language'] = item[3:].split('/')
if '片长:' in item:
time = [
search(r'[\d]*', x).group() for x in item[3:].split('/')
]
movie['time'] = sorted(time, reverse=True)[0]
# get top250 info
movie['rank'] = soup.find(class_='top250-no').get_text()
movie['number'] = soup.find(property='v:votes').get_text()
except Exception as e:
print(e)
return movie
gpg (GnuPG) 2.2.3; Copyright (C) 2017 Free Software Foundation, Inc.
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
请选择您要使用的密钥种类:
(1) RSA and RSA (default)
(2) DSA and Elgamal
(3) DSA (仅用于签名)
(4) RSA (仅用于签名)
您的选择?
选择 1:
RSA 密钥长度应在 1024 位与 4096 位之间。
您想要用多大的密钥尺寸?(2048)
选择 4096:
请设定这把密钥的有效期限。
0 = 密钥永不过期
= 密钥在 n 天后过期
w = 密钥在 n 周后过期
m = 密钥在 n 月后过期
y = 密钥在 n 年后过期
密钥的有效期限是?(0)
You need a user ID to identify your key; the software constructs the user ID
from the Real Name, Comment and Email Address in this form:
"Heinrich Heine (Der Dichter) "
真实姓名:
电子邮件地址:
注释:
当时大一,看到这个段子就笑了一笑,面对从一百多到一千多价位不等的机械键盘,还是比较理智的,听人说凯华轴的手感也是最接近 Cherry 轴的,于是就买了贼鸥 87,用了快两年,这期间:鼠标换了两个,耳机也买了两个,键盘却一直在用这一个,最近有几个键不灵了,正好趁着双十一,想着干脆换一把新的。心中对 Poker 那独特的键位种草已久,可惜京东没有 Poker II 的红轴版本,于是便入手了一代。
开机之后会发现进入 GRUB 的引导了,通常会包含至少三个选项(以 Manjaro 举例):Manjaro、Manjaro 高级选项和 Windows Manager。这就代表你已经完美的解决了 Windows 和 Linux 双系统引导的问题。
修复 Windows 引导
这一点是我安装 Arch Llinux 的时候发现的,Arch Linux 安装过程是手动安装的,在编写 GRUB 的时候会扫描不到 Windows Manager 所在的分区(当然可能不是所有人都会遇到),所以在 GRUB 界面可能会看不到 Windows Manager 选项,导致进不去 Windows 10,这里就需要手动编辑 GRUB 信息,我们打开 /boot/grub/grub.cfg 文件,发现里面确实没有 Windows 10 的启动信息,在后面加上:
]]>
使用 Service Worker 优化网站2017-07-25T13:06:47+08:002017-07-25T13:06:47+08:00urn:uuid:f879b895-7507-5f74-59ee-a1f353002b5f
静态博客的内容是很适合用缓存来加速访问的,除了采用常见的 CDN 加速和压缩博文等方法,通过客户端也可以实现加速访问,本文介绍的是「服务工作线程—— Service Worker」。关于 Service Worker 的具体介绍见
这里
。本文主要需要的是它的离线加载的特性。
本博客使用 Service Worker 可分为两个阶段,在我最初撰写本文的时候,使用的是 Service Worker 原生的接口。在不久之后,Google 推出了
sw-toolbox
和
sw-precache
用以让用户更全面的掌控 Service Worker 缓存的方式:包括版本控制、文件缓存级别、具体路径等,于是在我经历了漫长的实践后(其实是因为懒),有了本文 Version 2.0。
启用 Service Worker
添加注册代码
以下注册代码需要在网站的根目录添加,这样才能保证接管整个网站的全部资源。
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('/sw.js')
.then(function() {
console.log('A new service worker is being installed.');
})
.catch(function(error) {
console.log('Service worker registration failed:', error);
});
} else {
console.log('Service workers are not supported.');
}
将以上代码加入主题中,至于加在哪需要根据主题的结构决定。你只需要保证生成的静态资源中包含以上代码,那么就算添加成功。以 NexT 为例,你可以把以上代码添加到 ``/next/layout/_thrid-party/comments/ ` 下的任一评论配置文件中(前提是你开启了该评论组件)。
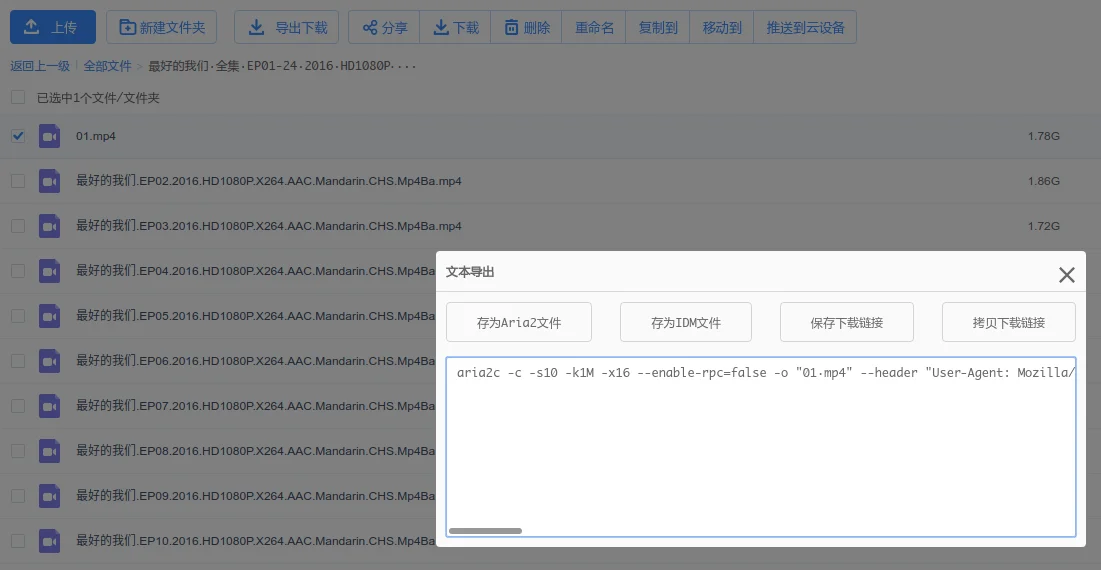
我为什么会想到要写一个下载器呢,实在是被百度云给逼的没招了,之前用 Axel 配合直链在百度云下载视频能达到满速,结果最近两天 Axel 忽然不能用了,于是我就想着要不干脆自己写一个吧,就开始四处查询资料,这就有了这篇博客。
我假设阅读这篇博客的你已经对以下知识有所了解:
Python 的文件操作
Python 的多线程
Python 的线程池
Python 的 requests 库
HTTP 报文的首部信息
下载
获取文件采用的是 requests 库,该已经封装好了许多 http 请求,我们只需要发送 get 请求,然后将请求的内容写入文件即可:
import requests
r = requests.get('http://files.smashingmagazine.com/wallpapers/july-17/summer-cannonball/cal/july-17-summer-cannonball-cal-1920x1080.png')
with open('wallpaper.png', 'wb') as f:
f.write(r.content)
随后看看文件夹,那张名为 wallpaper.png 的图片就是我们刚刚下载的。
但是这个功能太简单了,甚至简陋,我们需要多线程并发执行下载各自的部分,然后再汇总。
拆分
为了拆分,首先得知道数据块的大小,HTTP 报文首部提供了这样的信息:
用 head 方法去获取 http 首部信息,再从获取的信息提取出 Content-Length 字段(上文图片大小为 261258 bytes)
import requests
headers = {'Range': 'bytes={}-{}'.format(0, 100000)}
r = requests.get('http://files.smashingmagazine.com/wallpapers/july-17/summer-cannonball/cal/july-17-summer-cannonball-cal-1920x1080.png', headers = headers)
with open('wallpaper.png', 'wb') as f:
f.write(r.content)
part = size // nums
for i in range(nums):
start = part * i
if i == num_thread - 1: # 最后一块
end = file_size
else:
end = start + part
每个线程获取到的内容按顺序写入文件(file.seek() 调节文件指针)
def down(start, end):
headers = {'Range': 'bytes={}-{}'.format(start, end)}
# 这里最好加上 stream=True,避免下载大文件出现问题
r = requests.get(self.url, headers=headers, stream=True)
with open(filename, "wb+") as fp:
fp.seek(start)
fp.write(r.content)
嘛,线程多了起来就扔到线程池让它来帮我们调度。
封装
功能复杂了,用对象来封装整理一下:
class Downloader():
def __init__(self, url, num, name):
self.url = url
self.num = num
self.name = name
r = requests.head(self.url)
self.size = int(r.headers['Content-Length'])
def down(self, start, end):
headers = {'Range': 'bytes={}-{}'.format(start, end)}
r = requests.get(self.url, headers=headers, stream=True)
# 写入文件对应位置
with open(self.name, "rb+") as f:
f.seek(start)
f.write(r.content)
def run(self):
f = open(self.name, "wb")
f.truncate(self.size)
f.close()
futures = []
part = self.size // self.num
pool = ThreadPoolExecutor(max_workers = self.num)
for i in range(self.num):
start = part * i
if i == self.num - 1:
end = self.size
else:
end = start + part - 1
# 扔进线程池
futures.append(pool.submit(self.down, start, end))
wait(futures)



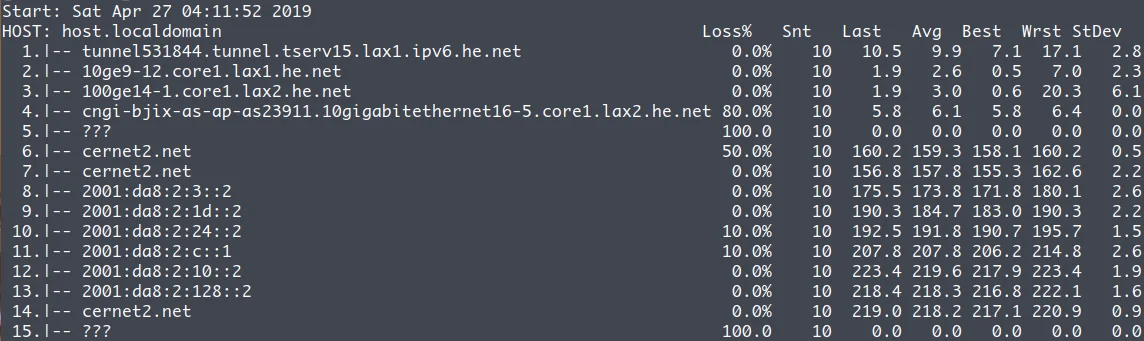


















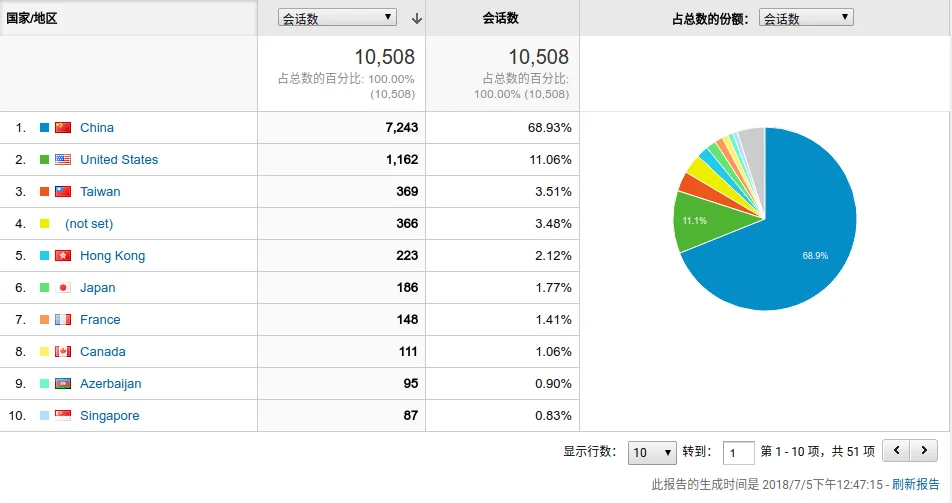
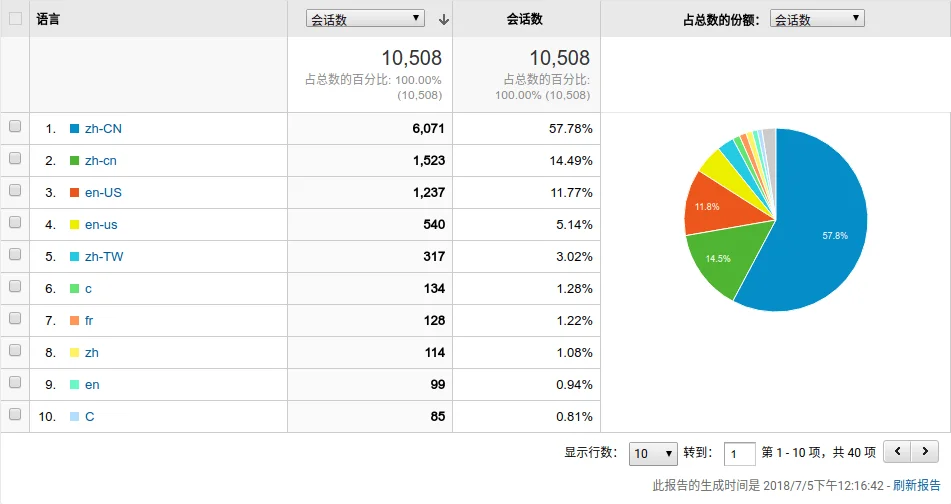
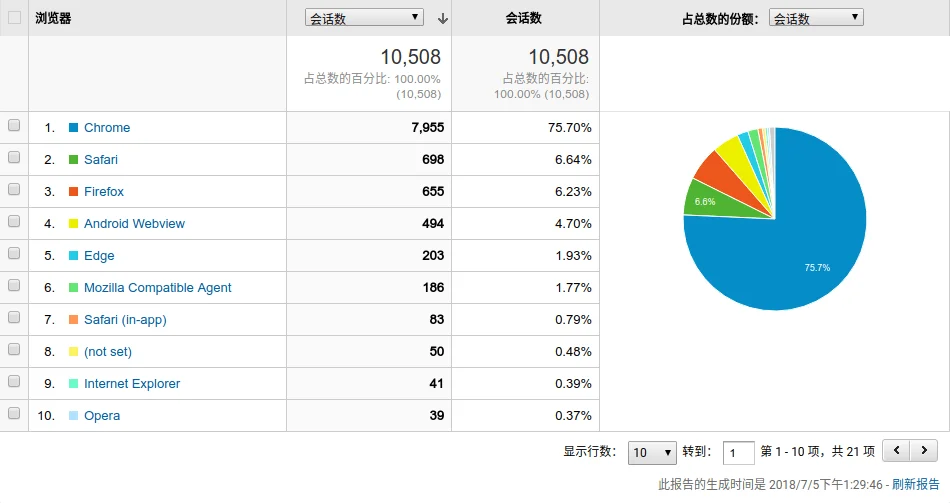
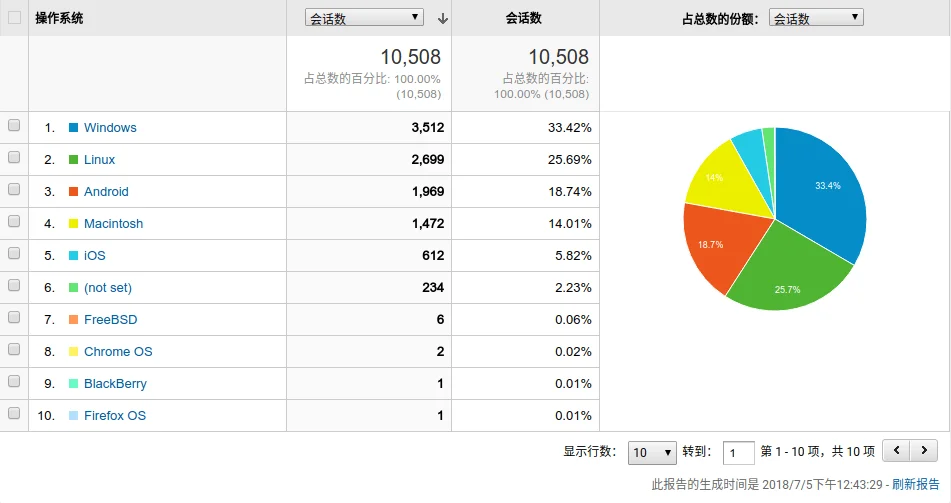
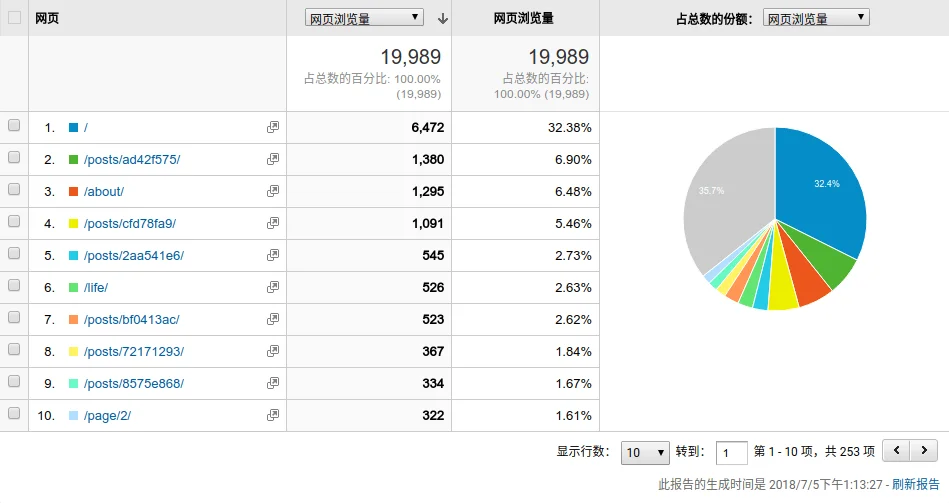





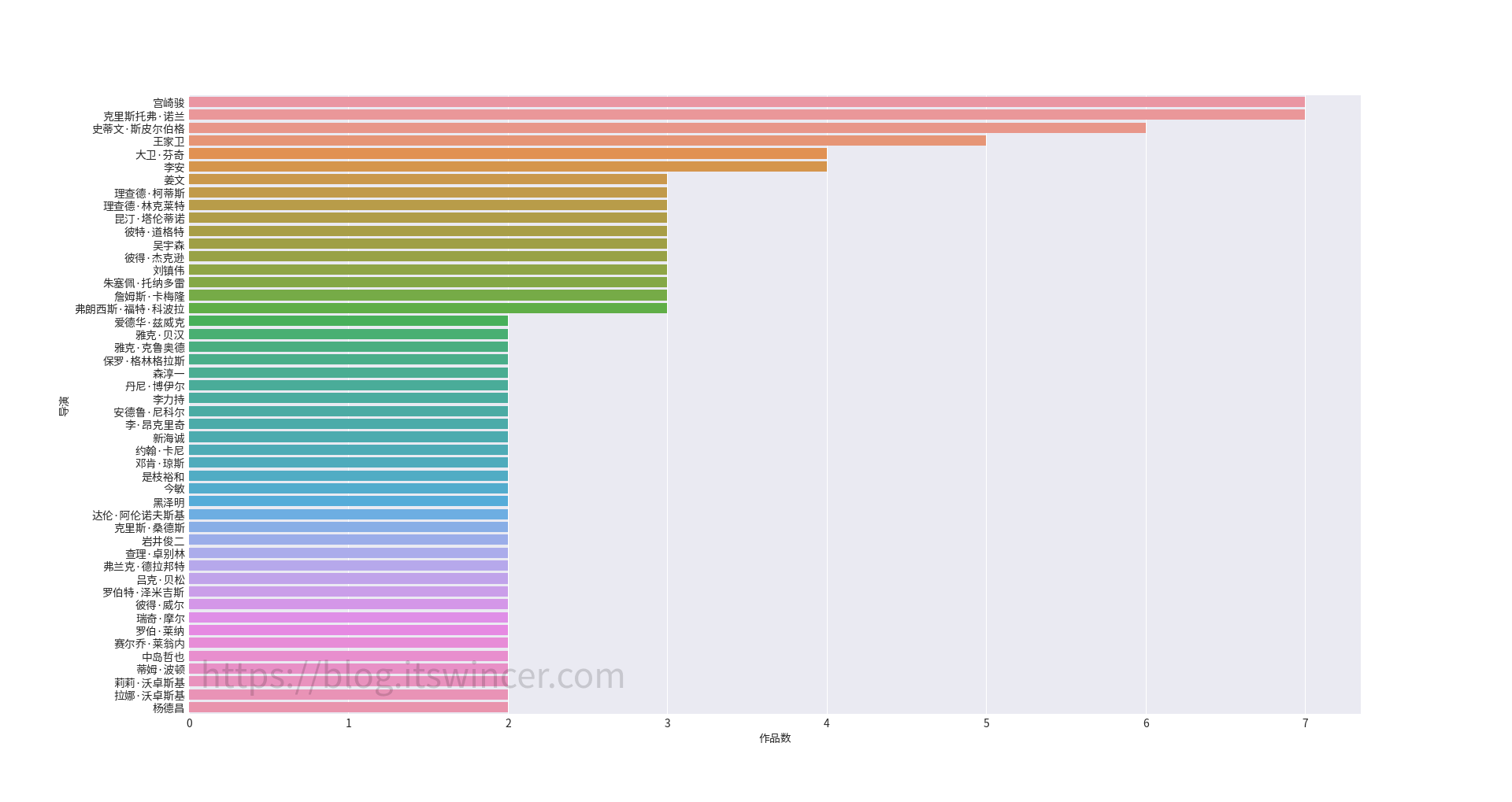
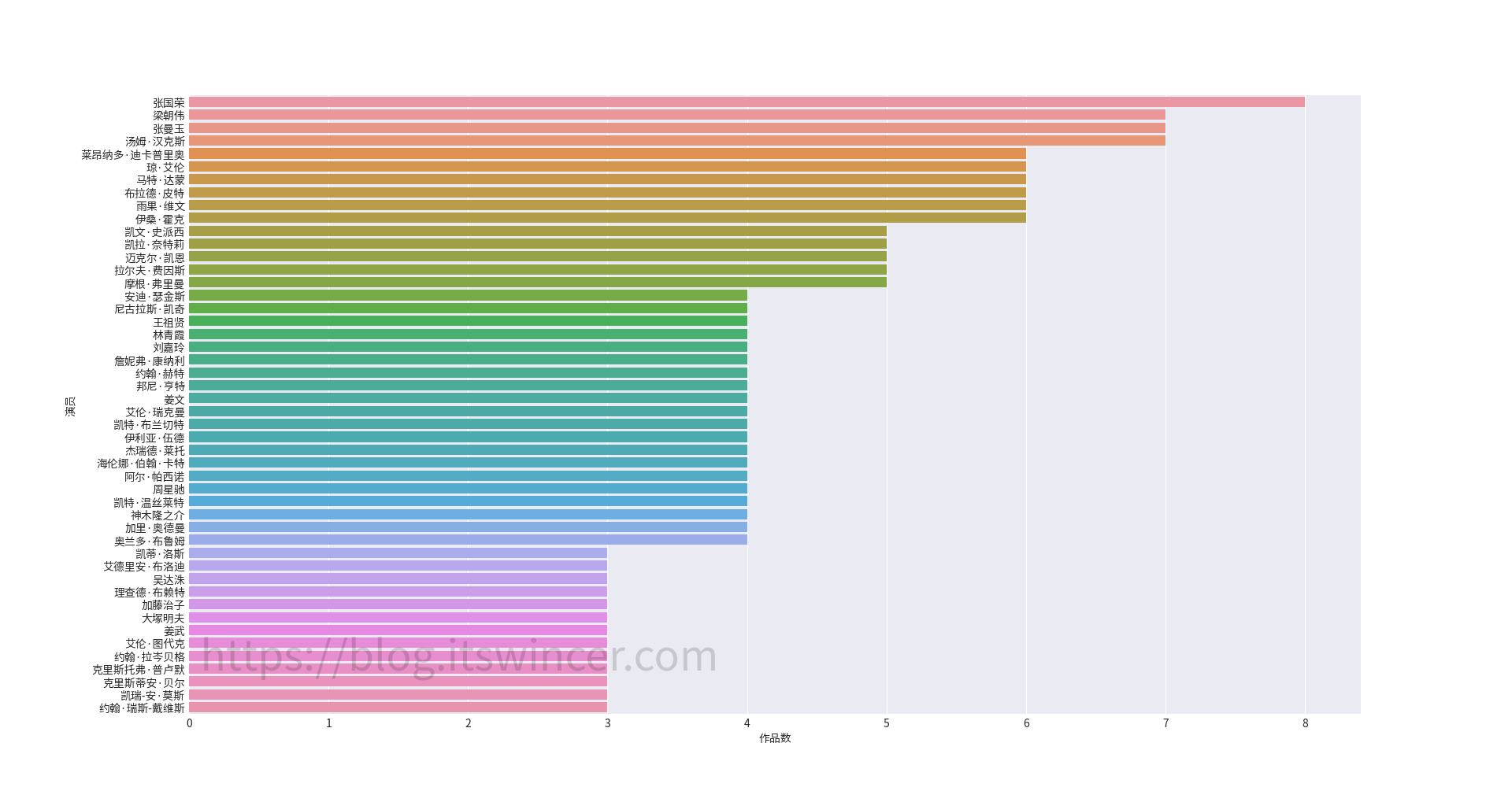
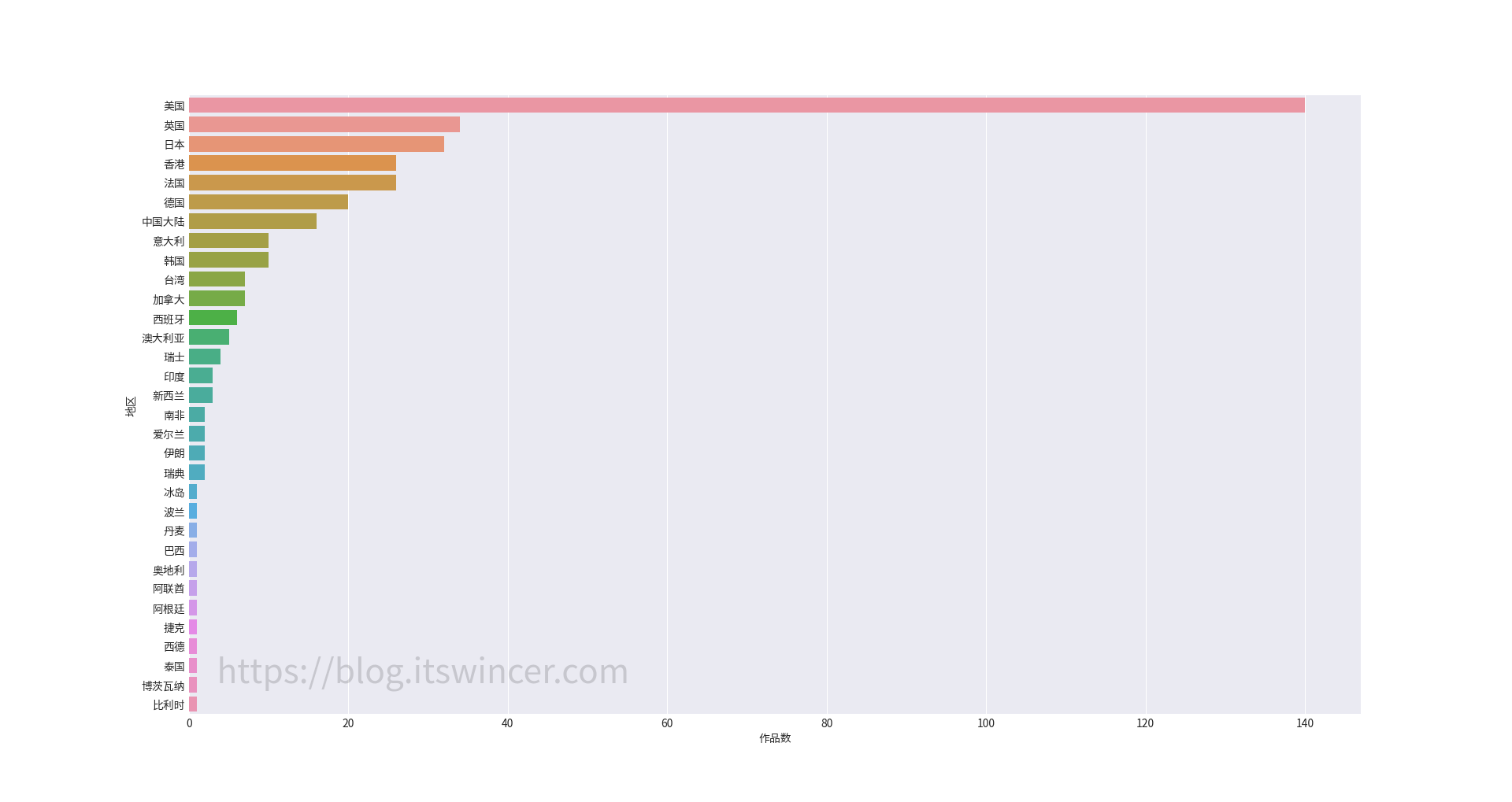
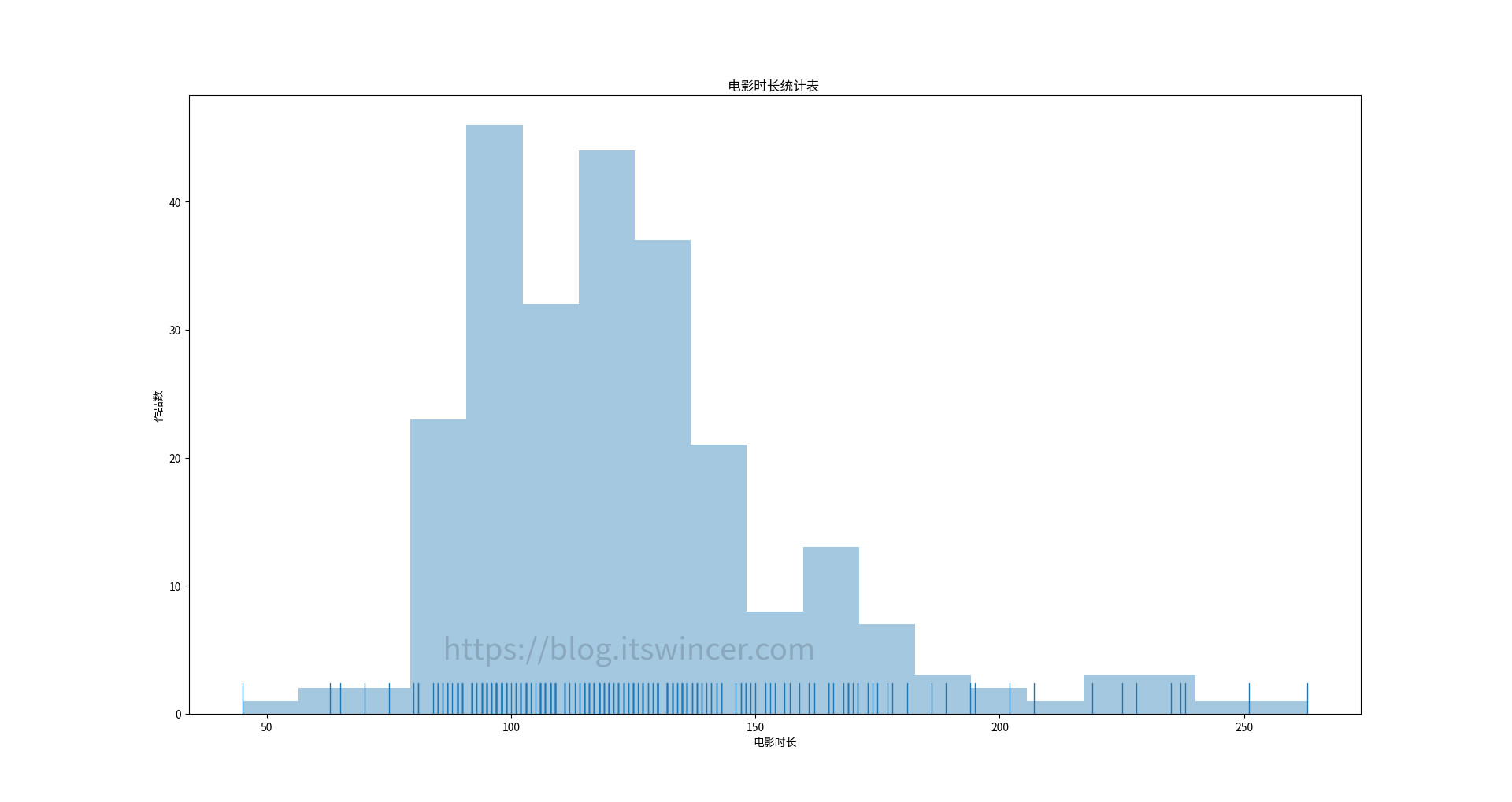
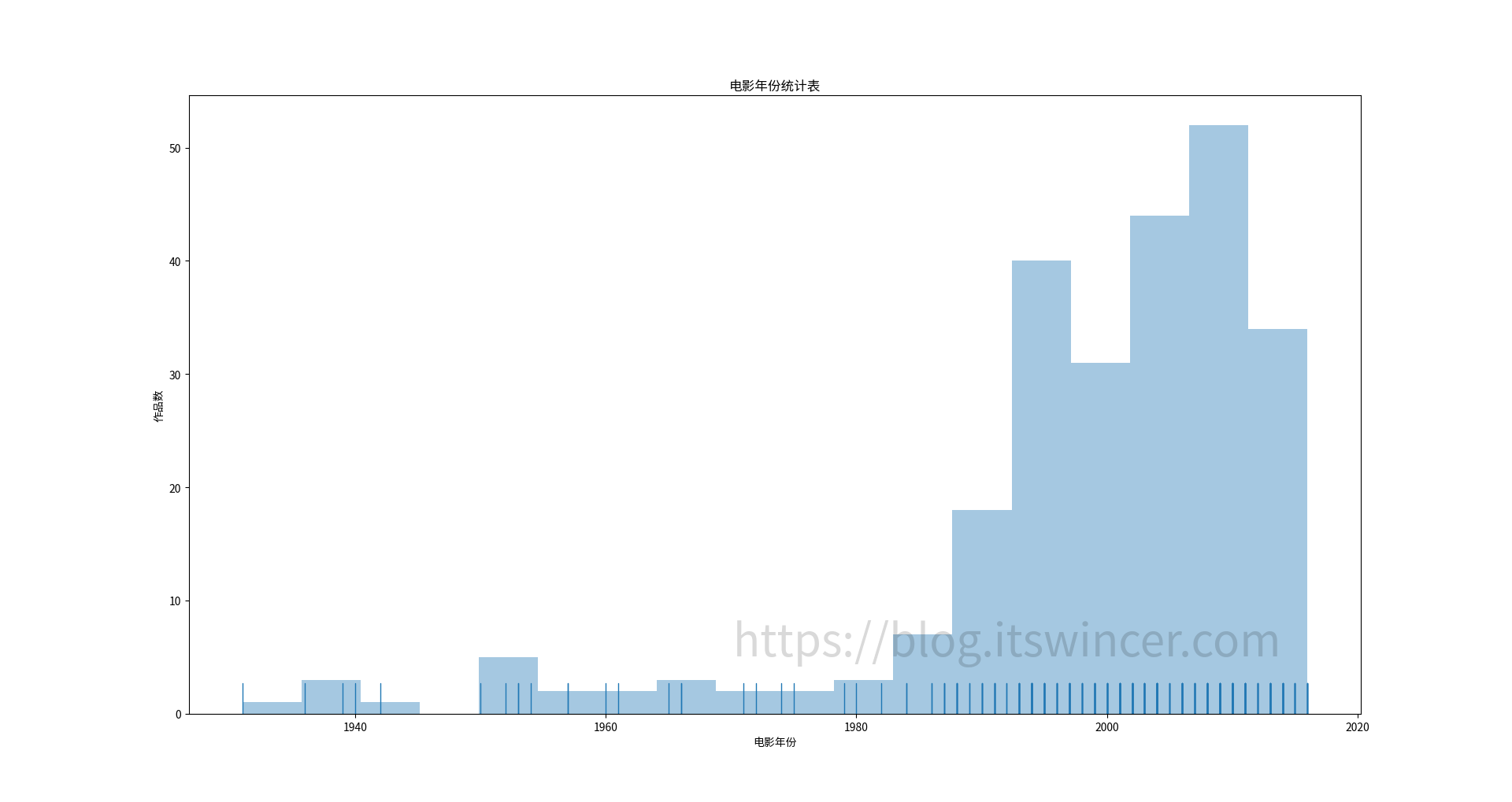
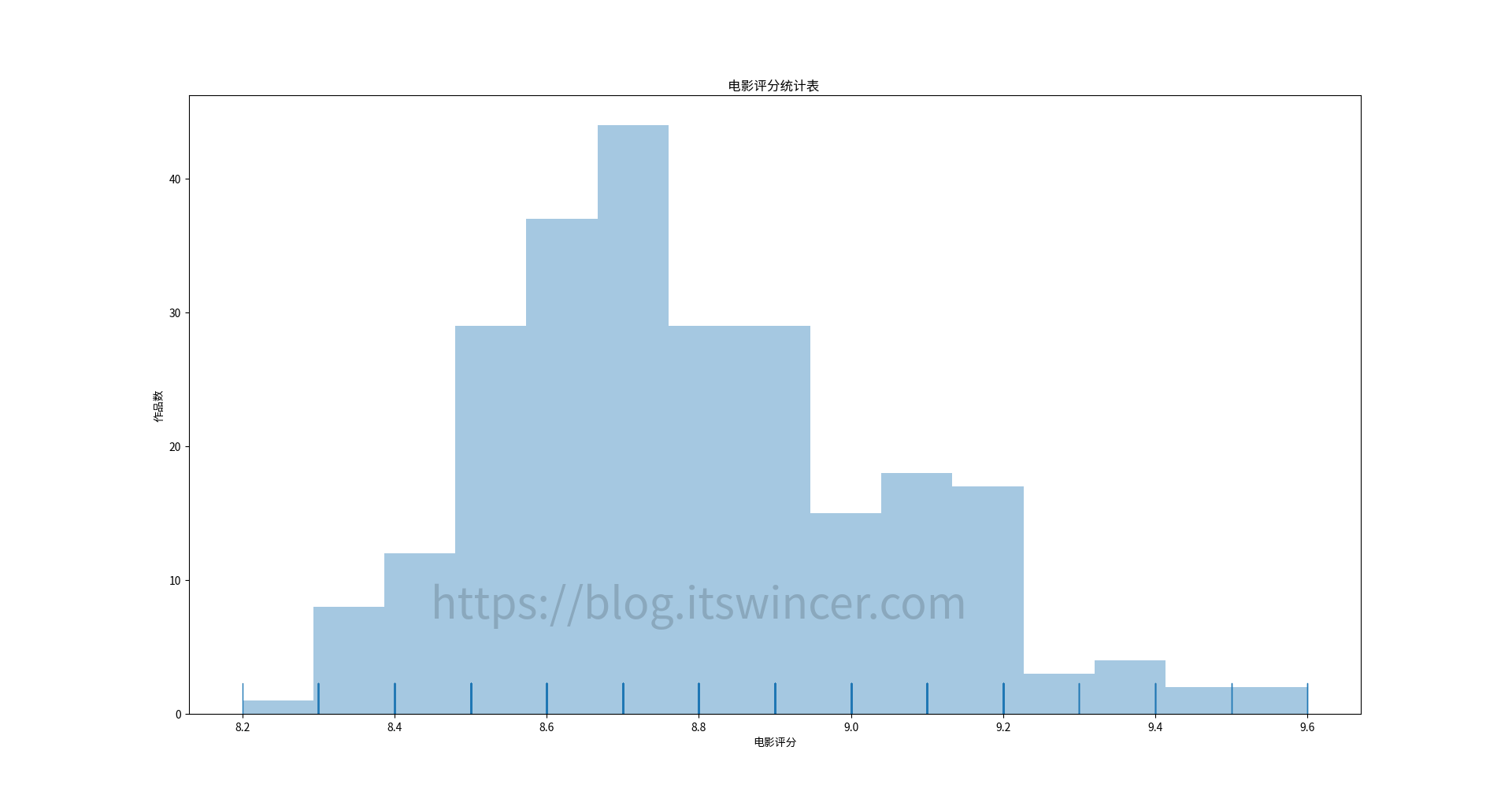









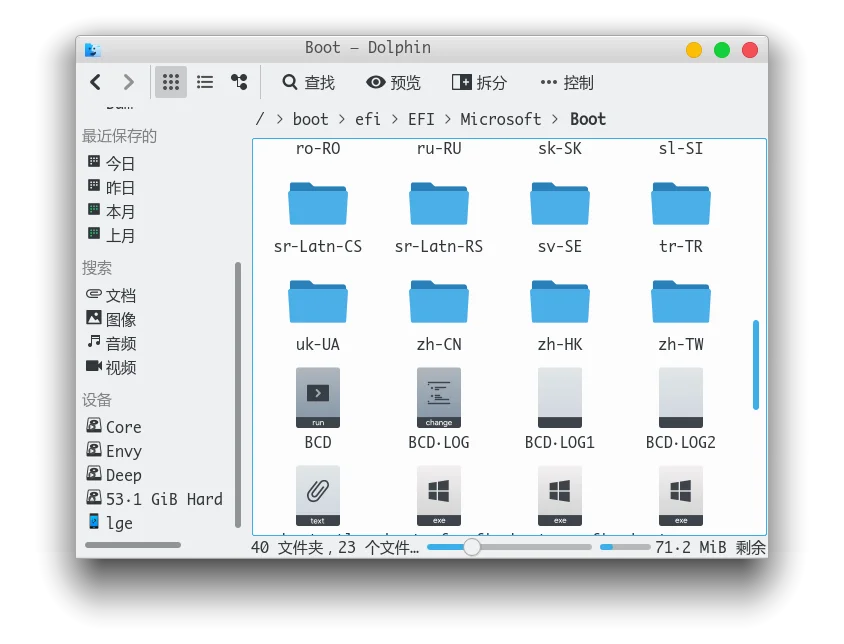
 可以看到,该分区包含 3 个文件夹(如果你没有装 Linux 的话,就只有两个),分别是 Boot、Microsoft 和 Manjaro,其中 Boot 文件夹就是 UEFI 引导所必需的文件。
我们继续打开
可以看到,该分区包含 3 个文件夹(如果你没有装 Linux 的话,就只有两个),分别是 Boot、Microsoft 和 Manjaro,其中 Boot 文件夹就是 UEFI 引导所必需的文件。
我们继续打开